「今」を映す大量のデータを分散処理で高速分析
「大量のデータを高速に分析する」というニーズを満たすために、多くのベンダーがさまざまな試みを行っている。アプローチとしては「スケールアップ」と「スケールアウト」の大きく2種類がある。
スケールアップは、分析にまつわるデータベースやDWHの性能を高めていく方法だ。ハードウェアとソフトウェアを組み合わせ、データ分析用途に最適化した高性能の「DWHアプライアンス」を使うようなソリューションがそれにあたる。一方のスケールアウトは、グリッドコンピューティングのような分散処理によるアプローチだ。
データ分析に関して、生熊氏は「大量のデータを分散処理するバックボーンとして、オープンソースのHadoop(ハドゥープ)がもてはやされている」と話す。
Hadoopは、Googleの検索エンジンを支える独自技術「MapReduce(マップリデュース)」の仕様を参考に開発された大規模分散処理プラットフォームである。リレーショナルデータベースで普通に処理した場合に何千時間もかかる処理を、並列分散処理(スケールアウト)によって数時間で完了してしまう。
MapReduceによる分散処理は、マスタが大規模データを小さく断片化して、スレーブに処理を割り当て(Map)、各スレーブの結果が結合されて、最終的な結果を生成(Reduce)してマスタに返すというイメージで行われる。
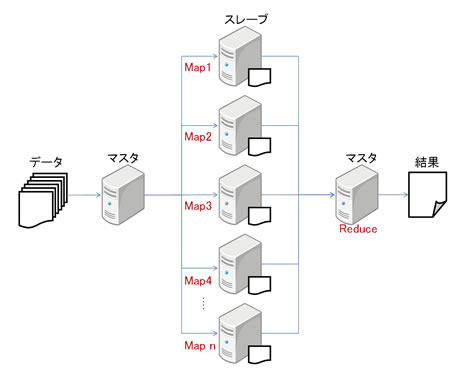 Hadoopにおける分散処理プロセスのイメージ
Hadoopにおける分散処理プロセスのイメージ
生熊氏は分析対象について、いわゆる基幹系システムのトランザクション(取引)データだけではなく「近年はケータイの通話記録を検索したり、ウェブのアクセスログを検索したりすることが多くなっている」と話す。ヤフーや楽天など、ウェブ系の企業がHadoopのユーザーとして知られている。Hadoopは大量のバッチ処理も得意だ。
こうしたユーザーの広がりに対応するかのように、既存のDWHベンダであるテラデータやネティーザも、すでにMapReduceに対応すると表明している。データベース最大手のOracleも技術情報サイト「Oracle Technology Network(OTN)」において、MapReduceを併用する方法に言及しているいう。生熊氏は「MapReduceが一般的になればなるほど、OracleやIBM、MicrosoftなどのRDBMS大手がMapReduceを取り込んでくる可能性が高い」と指摘する。
「今」を分析し、その場で意思決定し、アクションにつなげていく。そのためには「一部の専門的な知識と技術を持った分析担当者」の結果を待っていては間に合わない。専門でない人でも気軽に分析ができ、その結果をアクションに反映できるようなマンマシンインターフェースを持ったツールが必要だ。組織内の多くの人がBIを活用できるようにするためには、ユーザーライセンスもできるだけ低価格に抑える必要があるだろう。
今回はBIツールの最新動向についてアナリストの意見を聞いた。次回以降も、BIツールのより具体的な内容について見ていくことにしよう。





