データ管理とデータ構造
日々更新されるデータベースは、このまま分析することも可能ですが、運用パフォーマンスの低下や誤った操作などの防止のために、データウェアハウス(DWH)のような一元管理可能なサーバにまとめて格納するべきでしょう。DWHから特定のデータだけを抽出して、別に格納して作成したデータベースのことを「データマート」と呼び、これを用いて分析します。
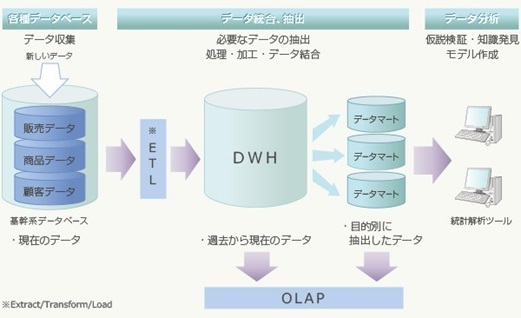
上記のように1カ所にデータが一元管理されていれば、データの散在も防止できますし、部署間のデータの融通といったことも必要がなくなり、業務効率にも役立ちます。
データマイニングの手順
分析するデータが整ったところで、実際にどのような手順を踏んでデータマイニングを実施すればよいのでしょうか。
主な流れとしては図のようなイメージです。
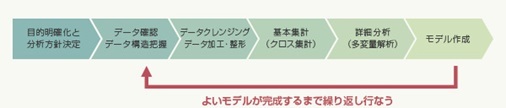
目的明確化と分析方針決定/データ確認、データ構造把握
この連載でも何度か指摘していますが、データ分析を実施する上で何も目的がなく、とりあえずデータがあるから分析して有用な知見を得ようと思っても、よい結果には結びつきません。たくさんのデータから何かしら知見を得ようとする探索的データマイニングにおいても、ビジネスにおける課題を理解し、何が明らかになれば解決できるのかという目的を定めます。
その目的を達成するために、データをよく見て内容を理解します。その上で、どのデータを用いてどのような分析手法やツールを使って分析するのか方針を立てます。
データクレンジング、データ加工・整形
前述したとおり、収集したデータにはほぼ必ずといってよいほど分析に不要なデータが混じっています。例えばデータの重複や欠損、本来扱うべきでないデータの混入、異常値などです。これらのデータを適切に処理し、分析用のデータに加工していきます。主に「前処理」と呼ばれる工程で、多くの実務者にとっての関門と言えるでしょう。
基本集計、クロス集計
本格的な分析に入る前に、まずはデータを俯瞰(ふかん)する必要があります。 前回説明したように基本統計量の算出、時系列での集計、クロス集計などを実施して、解決する課題のベースとなる数値を把握します。基本集計やクロス集計を実施することで、正しい現状理解が必要なのです。
多変量解析
分析方針の結果に基づき、回帰分析や主成分分析、因子分析、クラスタ分析などの手法を選択し、実施します。多変量解析の手法については今後の連載の中で触れていきたいと思います。
モデル作成
多変量解析の結果をもとに、ルールを一般化し、新たなデータに対してある一定のアルゴリズムで課題解決ができるモデルを作成します。また、機械学習のアルゴリズムの適用なども検討してもよいでしょう。ここで構築したモデルを実際のデータに当てはめてみて検証します。モデルが不適切であり、精度が低い場合は、パラメータをチューニングし、モデル自体を見直すことも必要でしょう。このような試行錯誤によって、データマイニングは実施されています。
今回はデータマイニングの概要や実際の手順などを解説しました。次回は分析した結果の可視化について説明します。
- 伊藤徹郎
- 金融機関で営業からモバイル開発までの幅広く経験。その後、ALBERTにデータ分析者として参画。レコメンデーションのアルゴリズム開発やECサイト、小売りなどのCRM分析、広告分析など、幅広いデータをあつかう。Tokyo.Rなどの社外コミュニティでも活動中。
Keep up with ZDNet Japan
ZDNet JapanはFacebook、Twitter、RSS、メールマガジンでも情報を配信しています。