富士通研究所は、仮想環境におけるネットワーク処理の主要機能である仮想ルーターを高速化する技術を開発した。
この技術は、仮想ネットワークのルーター機能を、論理回路を書き換え可能な大規模半導体デバイスFPGA(Field Programmable Gate Array)にオフロードして処理するとともに、性能ボトルネックであったパケット宛先制御を高速化する。
同技術を用いて、オープンソースの代表的な仮想ルーター「Tungsten Fabric」を、高速メモリーHBM2を搭載した「インテル Stratix 10 MX FPGA」上に実装し、汎用サーバー上でのオフロード効果を検証した。100Gbpsのイーサネットで接続したサーバー2台に仮想マシンを4台ずつ動かし、各仮想マシン間で通信を行って仮想ルーターの性能を測定したところ、従来手法では13.8Mppsだったパケット処理性能に対して、250Mppsと約18倍の高速化を実現した。また、使用CPUコア数も従来の13コアから1コアに削減した。
この技術を用いることで、アプリケーションのサーバー集約率を向上させることが可能となる。例えば、スタジアムにおける映像配信サービスがより少ないサーバー台数で運用できるようになるなど、5G(第5世代移動通信システム)時代の大量データを活用したインフラビジネスに大きく貢献するという。
開発した技術は、高速パケット宛先検索技術と検索テーブルのハイブリッドメモリー管理技術で構成される。
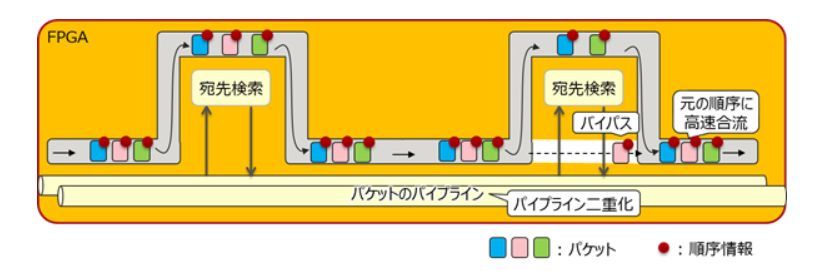
高速パケット宛先検索技術(出典:富士通研究所)
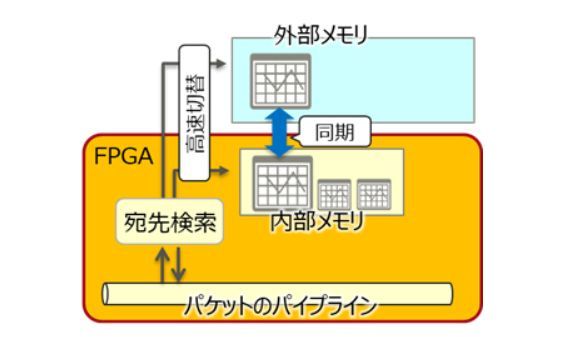
ハイブリッドメモリー管理技術(出典:富士通研究所)
高速パケット宛先検索技術は、パケットのパイプライン上でパケットと別に順序情報を保持し、多段にわたる宛先検索処理において前段検索の結果から不要となった次段検索をバイパスさせて合流させる際に、パケットのパイプラインの順序情報を基にパケットを元の順序に戻す。これにより、高速なパイプライン処理を維持しつつメモリーアクセスを低減させることができる。さらに、パイプライン処理を二重化することで、パケット処理性能を向上させることが可能となる。
従来は、パケット順を変更することなく全パケットで同じ処理を実施することで高速処理を行っていた。しかし仮想ルーター処理の入出力でパケット順が変わると、アプリケーションでは再送が発生し、品質低下やシステムの負荷増加につながっていた。
検索テーブルのハイブリッドメモリー管理技術は、高速で小容量なFPGAの内部メモリーと大容量の外部メモリーとを、宛先検索処理を止めずに自動的に切り替える。この自動切り替えは、接続数の増加に伴って検索テーブル群のメモリー使用量が増加して内部メモリーの空き容量が少なくなった場合に、容量当たりのアクセス頻度が低い検索テーブルをバックグラウンドで外部メモリーに同期しておくことで実現した。
これにより、検索処理を止めることなく外部メモリーの検索テーブルに自動で切り替わることが可能となる。大規模システムにおいて通信先が多く、大きな検索テーブルが必要な場合でも、外部メモリーへのアクセスを抑えて、安定したパケット処理性能を実現する。
富士通研究所では、ユーザーのDX(デジタル変革)ユースケースを想定した検証を進め、2021年度中の実用化を目指している。





