
生成型の人工知能(AI)に関して最も熱く交わされている議論の1つが、オープンソースとクローズドソースの比較だ。結局、どちらの方が価値が上なのか。
提供:magicmine/Getty Images
一方では、常に進化を続けるきら星のごときコントリビュータ―たちによって、数多くのオープンソースの大規模言語モデルが作られ続けている。その中でも特に有名なのが、Metaの「Llama 2」だ。一方、クローズドソースの大規模言語モデルの代表例は、商用モデルとして定評がある2つのモデルである、OpenAIの「GPT-4」と、ベンチャーキャピタルの支援を受けているスタートアップAnthropicの言語モデル「Claude 2」だろう。
これらのモデルをテストして互いに比較する方法の1つに、特定の分野(例えば医療知識)の質問に回答させ、その善し悪しを比べるというやり方がある。
権威のある医学論文誌を発行しているNew England Jounal of Medicineが創刊した新論文誌「NEJM AI」に最近掲載された、ペパーダイン大学、カリフォルニア大学ロサンゼルス校、カリフォルニア大学リバーサイド校の研究者らが執筆した論文によれば、そのテストで、Llama 2の腎臓学に関する質問に答える能力は残念なものであることが明らかになったという。
第一著者であるペパーダイン大学Data Science InstituteのSean Wu氏をはじめとする著者らは、「オープンソースのモデルは、GPT-4やClaude 2と比べて総正解数と説明の質の点で劣っていた」と述べている。
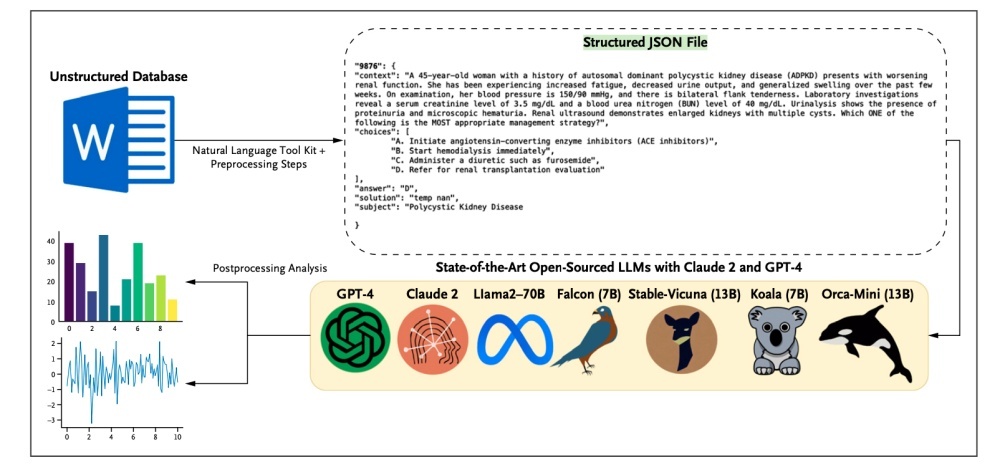
データ取得、処理、大規模言語モデルの利用のワークフローを示す図
提供:New England Journal of Medicine
論文には「GPT-4は非常に優れた成績を収め、ほとんどのテーマで人間と同様の成績を収めた」とある。GPT-4は、複数の選択肢から回答を選択する方式の腎臓学に関する問題で、人間の受験者の合格点である75%をわずかに下回る73.3%のスコアを獲得した。
著者らは「オープンソース大規模言語モデルの大半の総合スコアは、質問にランダムに回答した場合のスコアと変わらなかった」と述べ、5つのオープンソースモデルの中ではLlama 2が最も良い成績を収めたとした(5つの中には「Vicuna」や「Falcon」も含まれている)。しかしそのLlama 2のスコアも30.6%で、ランダムに回答した水準(23.8%)を少し上回っただけだった。
この研究は、AIの分野で「ゼロショット」と呼ばれている種類のタスクをテストするものだった。ゼロショットとは、正しい回答や間違った回答の例を与えず、修正も行わずに言語モデルを使用することを意味する。ゼロショットのアプローチを用いれば、言語モデルがトレーニングデータの中にはない新たな能力を獲得する能力である「コンテキスト内学習」の能力をテストすることができる。
このテストでは、Llama 2をはじめとする5つのオープンソースモデルと2つの商用モデルを対象として、「Nephrology Self-Assessment Program(nephSAP)」(米国腎臓学会が出版した医師の自習用教材)から抜粋された腎臓学に関する問題858件に回答させた。
著者らは、nephSAPのプレーンテキストファイルを言語モデルに入力できるプロンプトに変換するために、かなりの量のデータの準備作業を行う必要があった。それらのプロンプトには、自然言語で記述された問題と回答の選択肢が含まれていた(他の人が検証できるように、実際に使われたデータがHugging Faceで公開されている)。
さらに、言語モデルは多くの場合、回答として長文のテキストを出力するため、各モデルの回答を読み取って正解と比較し、出力結果を自動的に採点する技術を開発しなくてはならなかったという。





