GPUは次世代のデータベースに力を与えようとしている。GPUデータベースにはどのような特長があるのだろうか?また、独自の製品分野を確立できるのだろうか?
GPUは現在、目的のあいまいなデバイスとなっている。GPUはもともと、ゲーマー向けとして高いグラフィック描画性能を実現するために開発されたものだが、今では仮想通貨の採掘者から深層学習(DL)の専門家まで、さまざまな人々がその活用に目を向けている。
仮想通貨の採掘や、メモリモジュールに対する競合といった要因によってGPUへの需要が高まった結果、その価格は急騰している。これはユーザーにとってありがたくないニュースだが、NVIDIAのようなGPUメーカーにとっては素晴らしい話だ。
NVIDIAの変貌は、米国時間3月26~29日にカリフォルニア州シリコンバレーで同社が開催した年次イベント「GPU Technology Conference」(GTC)のアジェンダを見ても分かるはずだ。
AIやゲーム、暗号といった分野に手を染めていないという場合、なぜGPUに関心を抱くべきのだろうか?それは、GPUがデータベースの高速化にも役立つためだ。そして現在、データベースを利用していない企業などほとんど存在していないだろう。
GPUによる大規模並列処理
GPUは、並列処理が可能な処理を著しく高速化する。このアプローチは「Apache Hadoop」や「Apache Spark」といった大規模並列アーキテクチャでしばらく前から採用されている。これは、個々の独立したサーバ群の上でデータベースインスタンスを稼働させ、それらを連携させることで、マスターノードからそれぞれのデータベースインスタンスにサブクエリを委譲するという考え方に基づいている。
個々のサーバは並列でサブクエリを実行し、結果のデータセットをマスターノードに返却する。マスターノードはそれらの結果を組み合わせ、単一の結果としてクライアントに返すというわけだ。GPUを活用すれば、同様の分割統治アプローチが個々のサーバ内で可能になり、この場合にはCPUがマスターノードの役割を果たすことになる。
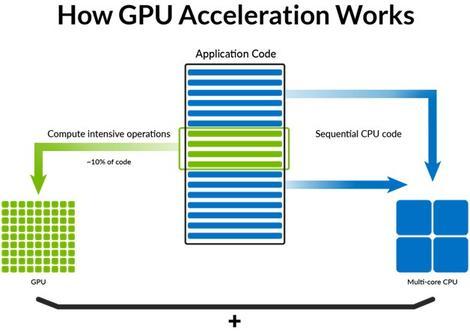
GPUはCPUと連携して並列処理を進めることで、分割実行が可能なワークロードを著しく高速化できる。
提供:SQream Technologies
では、データベースが稼働しているサーバにいくつかGPUを搭載するだけで、パフォーマンスの大幅な向上が期待できるのだろうか?話はそう簡単ではない。まず、あらゆるデータベース処理が並列に処理できるわけではない。並列処理ができない場合、GPUによる性能向上は期待できない。
しかも、並列実行が可能な処理であっても、データベース自体がGPUのアーキテクチャからメリットを引き出せるような設計と実装になっていなければならない。言い換えれば、GPUをフルに活用するには特殊なデータベースが必要になるということだ。





