マシンラーニングやディープラーニングでは、膨大なデータの「学習」と学習データから導く「推論」の2つの処理において膨大なコンピューティングリソースを必要とする。そのためのハードウェア開発では多くのIT企業が凌ぎを削り、その1つのGoogleは2013年から独自の専用プロセッサ「Tensor Processing Unit(TPU)」を開発する。同社が開催したメディアセミナーでは、最新世代のTPU 3.0に至るまでの道のりが語られた。
TPUは、Googleが2015年11月にマシンラーニングを開発するためのオープンソースライブラリとして公開した「TensorFlow」を実行するための独自のチップセットで、初代のTPU v1は2016年5月、2代目のTPU v2は2017年5月、TPU 3.0は2018年5月にそれぞれ発表。ほぼ1年ごとに世代が進化する。TPU v2から、多数のTPUを組み合わせた大規模システム「TPU Pod」を開発し、同時にTPU単体のリソースをインターネット経由する「Cloud TPU」(現在はGoogle Computing Platformで提供されるβ版サービス)も開始した。
TPU v1とTPU v2

Google Cloud デベロッパーアドボケイトの佐藤一憲氏
Google Cloud デベロッパーアドボケイトを務める佐藤一憲氏によると、TPUの開発構想は2006年ごろからあったという。Google内部でマシンラーニングでのニューラルネットワークの利用が広がるにつれ、当時の全てのデータセンターが持つコンピューティングリソースの2倍が必要になるとの見通しが判明したことから、ニューラルネットワークでの行列計算処理に特化したASIC(特定用途の集積回路)開発の必要性が高まった。
TPU開発の狙いは、あくまでディープラーニングの行列演算を低消費電力で高速に処理することにあったことから、TPU v1ではまず膨大なデータの「推論」処理のみとし、行列演算の最適化を図ることに重点が置かれた。開発は2013年に本格化し、2015年からまず検索、翻訳、画像などのサービスで実運用を開始した(公表は2016年5月)。1年強での実用化は、こうしたチップセットの開発では異例とも言えるスピードになる。
28ナノミリプロセスで製造され、動作周波数は400MHz、消費電力は40ワット。6万5536個の8ビット演算器が実装された。同時代のIntel Haswell(第4世代Intel Coreプロセッサ)に比べ、行列演算の処理性能は15~30倍、電力性能としては30~80倍だったという。
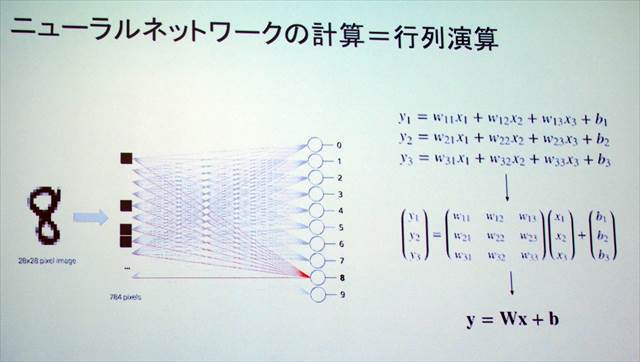
最適化においては、研究から汎用性が求められる32ビットプロセッサほどの計算精度を必要としないことが分かり、16ビットで「学習」、8ビットで「推論」の処理を行う。また、行列演算の高速化では「シストリックアレイ」と呼ばれるアーキテクチャで、行列演算を並列・連続的に行う。
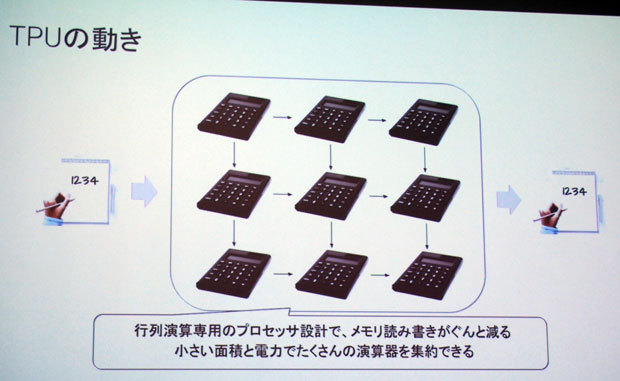
「Tensor Processing Unit(TPU)」の動作イメージ
続くTPU v2は「学習」処理が追加され、3万2768個の16ビット演算器で構成される。ユニット単体では最大180テラフロップスの浮動小数点演算が可能になり、64ユニットのTPU v2で構成されるTPU Podは、11.5ペタフロップスを記録する。米スタンフォード大学が公開しているディープラーニングのベンチマーク「Dawnbench」でのResidual Network(ResNet)-50を用いた評価では、精度93%での学習時におけるCloud TPUのコストが7ドル50セントとされ、これはGPUを用いる場合の約10分の1程度になるという。また、学習に要する時間はTPU Podの半分のリソースで最速となる30分だった。
機械学習は誰でも利用できるサービスに
2018年5月に発表した最新のTPU 3.0では、冷却方法が空冷から水冷に変更されたことで、TPU v2よりも高密度実装が可能になった。TPU 3.0単体の処理性能は公表していないが、TPU PodとしてはTPU v2比で約8倍の100ペタフロップスになるという。Googleは、2018年中にTPU v2ベースのTPU PodによるCloud TPUサービスの提供を予定。ただ、現時点でTPU 3.0単体およびTPU 3.0ベースのTPU PodによるCloud TPUサービスの提供はしていない。
佐藤氏によれば、TPUは、マシンラーニングの技術をだれもが容易に利用できるサービスとして提供するためのコンピューティングリソースという位置付けであり、一般への外部販売などは計画していない。将来的な利用の拡大に向けては、2017年11月に組み込みデバイスでTensorFlowを利用できるようにするフレームワーク「TensorFlow Lite」を発表。Androidスマートフォンなどのデバイス側でも推論処理が可能になり、AIサービスのさらなる拡大を目指していくと説明している。