人工知能(AI)と機械学習の急増が、コンピューティングの本質そのものを変えつつあるとの見解を、AIを最も大規模に活用している企業の1つであるGoogleが示した。
Googleのソフトウェアエンジニア、Cliff Young氏は米国時間11月1日午前、半導体分野の調査会社として名高いThe Linley Groupがカリフォルニア州サンタクララで開催した、人気のコンピュータチップに関するシンポジウム「Linley Group Fall Processor Conference」で、開会の基調講演を行った。
Young氏はまず、AIの利用が「指数関数的段階」に達した時期が、数十年前に提唱された半導体の進歩に関する経験則「ムーアの法則」が行き詰まった時期と完全に一致していた点を指摘した。
Young氏は「いささか神経質な時代だ」と、自らの現状認識を披露した。「デジタルCMOSは鈍化し、Intelの10nm(チップ製造プロセス)への取り組みが難航する中で、GLOBALFOUNDRIESは7nmプロセス導入をあきらめつつある。このような状況と期を同じくして、ディープラーニング(深層学習)が興隆し、経済的需要が生じた」。CMOS(相補型金属酸化膜半導体)は、コンピュータチップの最も一般的な材料だ。
従来型チップが性能と効率の向上に苦闘する一方で、AI研究者からの需要は急増しているとして、Young氏はいくつかの統計データを列挙した。コーネル大学が運営する論文公開サイト「arXiv」に登録される機械学習に関する学術論文数は、18カ月ごとに2倍に増えている。同様に、AIに焦点を当てたGoogleの社内プロジェクトの数も、18カ月ごとに倍増しているとYoung氏は述べた。さらに勢いがあるのが、機械学習に使われるニューラルネットワークの実行に必要な浮動小数点演算で、その演算数は3カ月半ごとに倍増している。
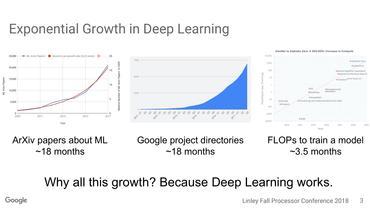
このようなコンピューティングへの需要増加すべてが、「超『ムーアの法則』」につながっている、とYoung氏は言う。同氏はこの現象を「いささか恐ろしい」「少し危険な」「心配すべきもの」と表現した。

AI分野で「なぜこれほどの指数関数的成長が起きているのか?」と同氏は問いかけ、その理由を以下のように考察した。「1つには、ディープラーニングが成果を出している点が挙げられる。私は長い間、自らのキャリアを通じて機械学習を無視してきた。こうしたものが軌道に乗るのかどうか、はっきりしなかったからだ」
だが、画像認識をはじめとする分野で、飛躍的進歩が続々と起き始め、ディープラーニングが「信じられないほど効果的」であることが明らかになったと、Young氏は振り返った。「この5年間のうちほとんどの期間、GoogleはAI最優先の企業だった。(検索から広告までの幅広い分野で)当社は事業のほとんどをAIベースに再編した」
AI研究を主導するGoogle Brainチームからの要望は「巨大マシン」だ、とYoung氏は述べた。たとえば、ニューラルネットワークはしばしば、採用する「重み」、すなわち、ニューラルネットワークに適用されてデータ操作の方向性を決める変数の数で評価される。
従来のニューラルネットワークでは、計算が必要なこうした重みの数は何十万、多い場合でも何百万単位に収まっていたのに対し、Googleの科学者は「テラ単位の重みに対応するマシン」、つまり、1兆個の重みを計算できるコンピュータを求めているという。こうした要求が生まれるのは、「(ニューラル)ネットワークの規模を倍増するたびに、精度が向上する」からだ。AIにおいては飽くなき規模の追求がもはや鉄則となっている。
周知の通り、こうした要望に応えるためにGoogleが開発してきたのが、独自の機械学習用チップ「Tensor Processing Unit」(TPU)だ。従来のCPUやグラフィックチップ(GPU)では高まる要求に応えられないため、TPUや類似のパーツが必要とされたというわけだ。
「長い間、我々は気持ちを抑え、IntelとNVIDIAは高性能システムの構築に非常に秀でた手腕を持っているとの見解を示していた。だが、5年前に我々は(両社に対応可能な)レベルを超えた」とYoung氏は述べた。
2017年にTPUのスペックが公表された際には、従来のチップをはるかに上回る性能をうたっていたことから、業界に大きな衝撃が走った。Googleは現在、第3世代のTPUを開発し、社内で利用すると同時に、「Google Cloud」を通じてオンデマンドの演算ノードとして提供している。

GoogleはTPUのインスタンスを拡大し続けている。なかでも「ポッド」構成は、1024個のTPUを接続して、新しいタイプのスーパーコンピュータにするというものだ。さらにGoogleはこのシステムの「規模拡大を続ける」意向だと、Young氏は明らかにした。
「我々は、数十ペタバイトの演算を行う、こうした巨大なマルチコンピュータを開発中だ。多くの方面で絶え間なく進歩を推進し、TeraOPSは上昇の一途をたどっている」
こうしたエンジニアリングでは「スーパーコンピュータの設計において生じるレベルの、あらゆる問題が発生する」とYoung氏は語る。
たとえば、Googleのエンジニアは、伝説的なスーパーコンピュータメーカーのCrayが用いた手法も採用している。Googleではニューラルネットワークコンピューティングの演算でも特に負担の大きい部分を担うチップ「巨大行列積ユニット」を「汎用ベクタユニット」および「汎用スカラユニット」と統合しているが、これはCrayにならったものだ。「スカラユニットとベクタユニットを組み合わせることにより、Crayは他のどのマシンよりも高い性能を実現した」とYoung氏は指摘した。
Googleは、チップのプログラミングに関しても、独自の新しい数値形式を開発してきた。「bfloat16」は、ニューラルネットワークにおける数値演算の効率を高める実数表現方式で、口語では「brain float」と呼ばれている。
TPUは、メモリチップについても最速の「HBM(high-bandwidth memory)」を採用している。ニューラルネットワークの訓練によって、必要とされるメモリ容量が急増していると、Young氏は語る。
「訓練では、メモリの使用頻度が急激に上昇する。何億件単位の重みについてはよく話題に上るが、(ニューラルネットワークの)アクティべーション(変数)の処理という問題もある」とYoung氏は述べた。
さらにGoogleは、ハードウェアの性能を最大限に活用すべく、ニューラルネットワークのプログラム方法にも調整を加えている。具体的には、「Mesh TensorFlow」などのプロジェクトで「データとモデルの並列処理に重点的に取り組んでいる」という。Mesh TensorFlowは、「ポッド規模でデータとモデルの並列処理を組み合わせる」同社の「TensorFlow」プログラミングフレームワークを応用したものだ。
ただし特定の技術に関する情報に関しては、Young氏はその詳細を明かすことはなかった。チップ周りのデータの移動方法である「相互接続」に関して、Googleがこれまで多くを語らず、「巨大なコネクタがある」と説明するだけにとどめてきた点にも同氏は触れた。しかし同氏はそれ以上の情報を提供するのを避け、これには聴衆からも笑いが起きていた。
Young氏の話は、そう遠くない未来に実現する可能性がある、さらに興味深いコンピューティングの領域にも及んだ。たとえば、入力データを1と0ではなく連続値として処理する回路を持つ、アナログチップを用いたコンピューティングが、重要な役割を果たす可能性があるという。「おそらくアナログ領域からサンプリングするようになるだろう。アナログコンピューティングを用いる物理学や不揮発性技術には、実に興味深いものがある」
Young氏はさらに、今回講演を行ったLinley Group Fall Processor Conferenceに出展しているような、新興チップ企業発の新技術にも期待感を示した。「非常に素晴らしい新興企業がある。デジタルCMOSで可能なことには限界があるので、我々は新たな取り組みを必要としている。こうした企業への投資が行われるようになってほしいと期待している」
この記事は海外CBS Interactive発の記事を朝日インタラクティブが日本向けに編集したものです。





