Amazon Web Services(AWS)は米国時間11月11日、データクレンジングツール「AWS Glue」を拡張した「AWS Glue DataBrew」の提供を発表した。DataBrewは、データの準備に必要となる一部の手順を視覚的なユーザーインターフェース(UI)によって自動化し、コーディング作業に携わらない人々のタスクをシンプルなものにするという。
DataBrewは、データアナリストやデータサイエンティストによるデータ抽出、加工、ロード(ETL)と呼ばれる作業を支援するツールだ。ETLはデータウェアハウスやその他のリポジトリーでデータが分析される前の工程となる。
Glueは2016年に発表された。Glueがコーディング作業を必要とする、エンジニア向けの視覚ツールだった一方、DataBrewはデータアナリストやデータサイエンティストがボタンのクリックや入力フィールドからの指示といった視覚的なUIだけで同様のクレンジング処理を実行できるようにするツールを目指している。
AWSはこの新たなツールについて、「従来であれば何日、あるいは何週間もかけてエンジニアが変換機能をコーディングしていたが、(このツールが提供する)250を超える組み込み変換機能によって、データの準備タスク(異常のフィルタリング、フォーマットの標準化、無効な値の修正など)を自動化できるようになる」と説明している。
AWSはDataBrewツールのデモ動画を公開している。動画では、データベースエントリー中に含まれているものの、データ分析に使用できないアンパサンド(&)などの特殊文字の削除方法が例として説明されている。
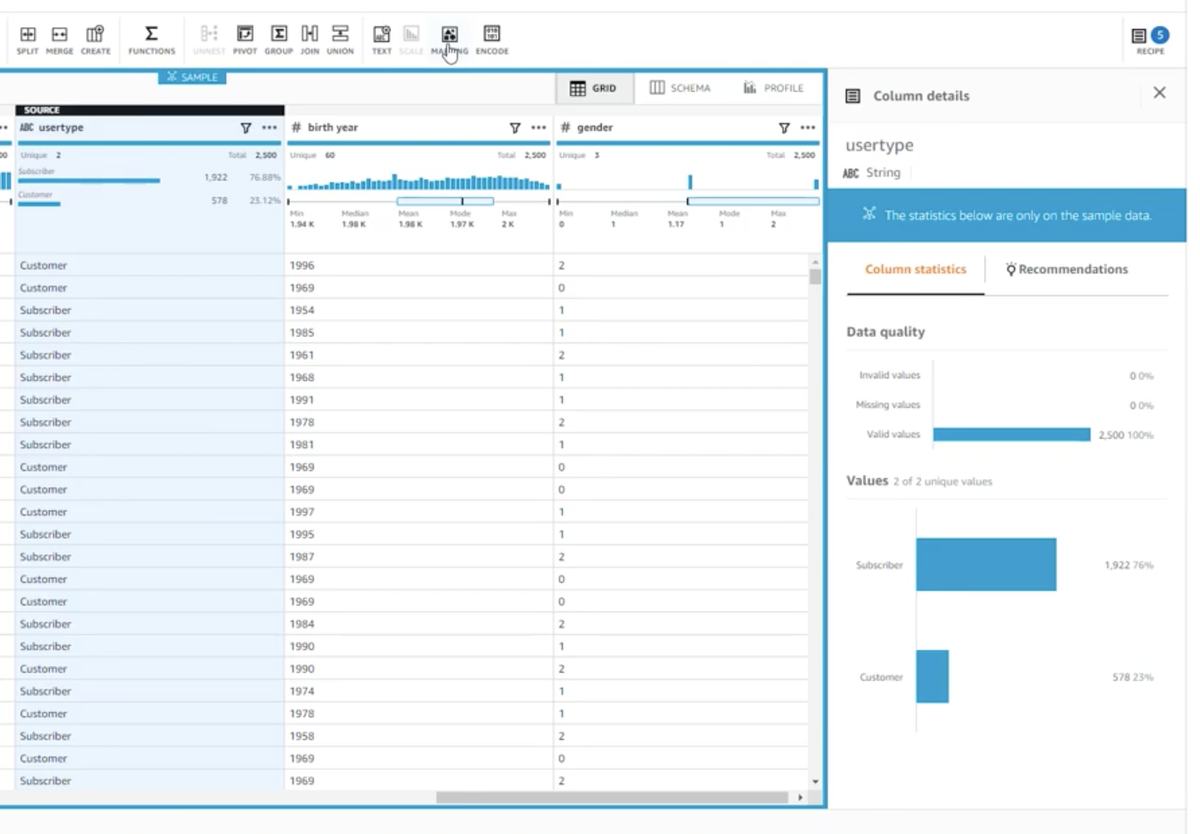
また、エントリーの分析を容易にするために、テキスト文字列を「カテゴリカルマッピング関数」によって数値へとマッピングする操作の説明も含まれている。
例えば、「subscriber」(購読者)と「customer」(顧客)のいずれかのエントリーを含む「user type」(ユーザー種別)といったカラムがある場合、画面のマッピングボタンをクリックし、全ての文字エントリーを「1」と「2」という値に対応させた新カラムを生成するよう指示した上で、「Apply」ボタンをクリックすれば、「1」と「2」という値にマッピングされたカラムが生成される。
また、データセット内で欠けているエントリーの数といった、対象データセットに関する統計情報を取得するプロファイリング関数も用意されている。
Amazonのイニシアチブは、Talendなどのデータクレンジングを専門とする企業にとって新たな競合対象となる可能性もある。
Amazonは、NTTドコモやエネルギー大手のBPなど、一部の企業がこのソフトウェアを利用していると述べている。
さらなる詳細は、Glue DataBrewnに関するブログ記事でも確認できる。
この記事は海外Red Ventures発の記事を朝日インタラクティブが日本向けに編集したものです。





