
コンテンツ配信ネットワーク(CDN)のCloudflareは米国時間6月21日、同日に発生した大規模障害について原因を発表し、謝罪を表明した。障害は保守性を重視する新しいアーキテクチャーへの移行作業中に発生したとしている。
同社によると、障害は東京や大阪を含む世界19カ所のデータセンターを結ぶ内部ネットワークを「Multi-Colo PoP(MCP)」と呼ぶ新しいアークテクチャーの構成に移行する作業中に発生した。MCPは、内部ネットワークにメッシュを構成する追加的なルーティングといい、これによって顧客サイトへの接続性を損なうことなく保守作業効率を高められるため、18カ月をかけて実装を準備してきたとしている。
移行作業は、協定世界時(UTC)の6月21日午前3時41分(日本時間同日午後12時41分)に開始し、19カ所のデータセンターに展開した午前6時27分(日本時間午後3時27分)に通信障害が発生した。午前6時58分(日本時間午後3時58分)に設定を元に戻す復旧作業に着手し、午前7時42分(日本時間午後4時42分)に復旧作業を終え、午前8時(日本時間午後5時)に障害対応を完了したという。
障害の影響が及んだのは同社ネットワークの4%だったものの、通信リクエストでは50%に及んだといい、世界各地でCloudflareのサービスを利用している膨大なウェブサイトへのアクセスなどが一時できなくなった。
同社は、MCPへの移行作業手順に問題があったとして、障害の影響を受けた顧客に謝罪した。なお、MCPはサービスの可用性を高める重要なものだとし、再発防止のために各種作業手順などを見直して慎重に移行を行っていくとしている。
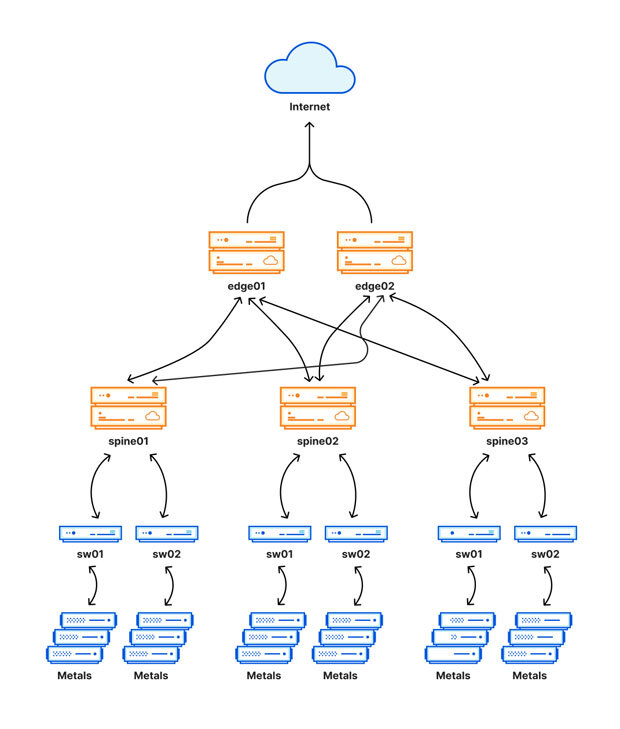
新アーキテクチャーのイメージ(出典:CloudFlare)




