フルスタックAIプラットフォームベンダーSambaNova Systemsは9月19日、新しい半導体「SN40L」を発表した。同社の大規模言語モデル(LLM)プラットフォーム「SambaNova Suite」を強化する。
SN40Lは、言語モデルに最適化され、シングルシステムノードでシークエンス長が25万で、5兆個のパラメータを扱うことが可能。TSMCの5nmテクノロジーをベースとし、104.3Kmのワイヤー長、1026億個のトランジスターを持つ。同社「Cerulean」アーキテクチャーに基づく再構成可能なデータフローユニット(Reconfigurable Dataflow Unit:RDU)コアを1040個搭載し、638TFLOPS(bf16)という性能を備える。
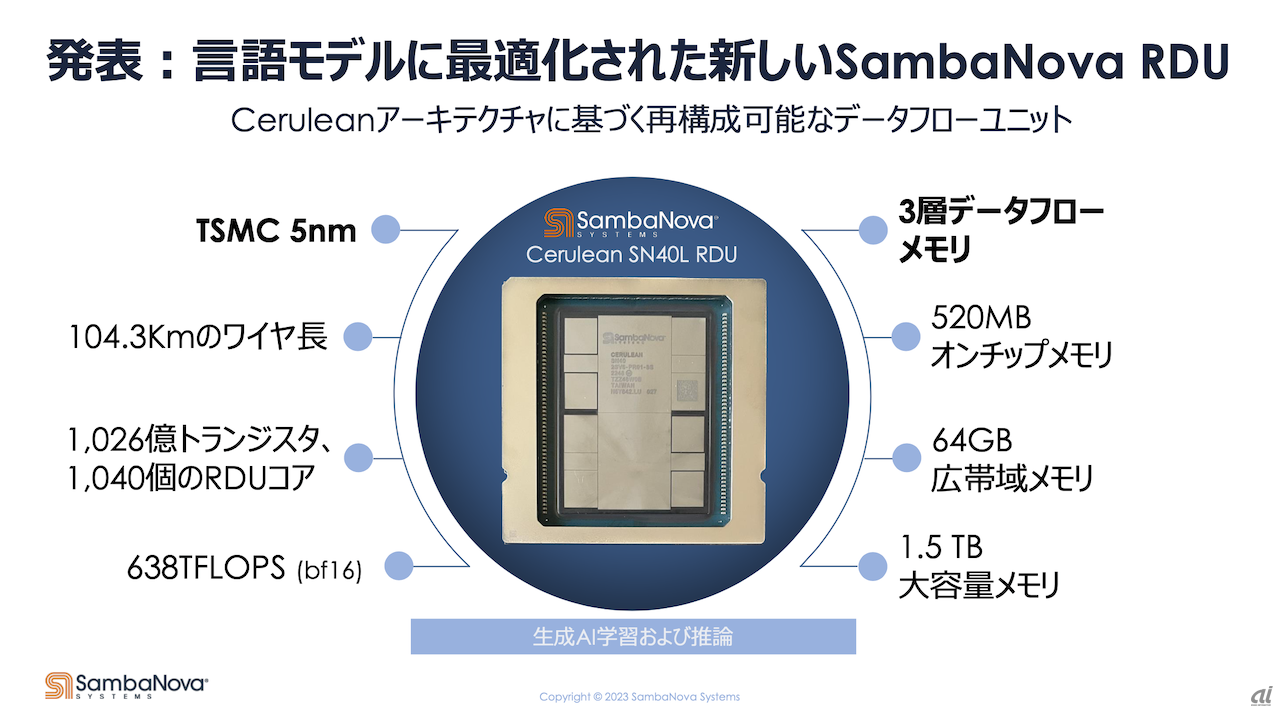
SN40Lの特徴の一つとして、同社で製品担当上級副社長を務めるMarshall Choy氏は、3層データフローメモリーの採用を挙げる。従来は高速なオンチップメモリーと大容量のDDRメモリーという2層だったが、Ceruleanベースのアーキテクチャーでは中間層として広帯域メモリー(HBM)を加えて3層としているという。
オンラインで発表会見に参加し、SN40Lを手にするMarshall Choy氏
3層のデータフローメモリーにより、学習性能はワークロードにもよるが1.5〜2倍以上まで向上し、推論性能も大幅に改善しているとChoy氏は述べ、1兆パラメータ級で300トークン/秒の推論性能を持ち、「NVIDIA DGX H100」と比べて推論スループットは2.5倍とアピールする。
SN40Lの発表とともに、SambaNova Suiteの機能強化も明らかにした。SambaNova Suiteは、オンプレミスまたはクラウドで展開可能で、半導体からモデルまでが統合されている。今回、事前学習済みファンデーションモデルが「Bloom 176B」「Llama-2 7B/70B」にも対応した。
また、ベクトルベースの検索補完生成(RAG)のための新しい埋め込みモデルは、ユーザーの文書をベクトル埋め込みに取り込むことを可能にし、Q&Aの過程で検索することができ、ハルシネーション(幻覚)を防ぐ。その結果をLLMにより情報を分析、抽出、要約できる。
他には、音声データの書き起こしおよび分析する自動音声認識モデル、マルチモーダルおよび長いシーケンス長の機能の追加、3層のデータフローメモリーによる推論にも最適化されたシステムなどが含まれる。

鯨岡俊則氏
アジア太平洋地域ゼネラルマネージャーを務める鯨岡俊則氏は、生成AIに関する現在のトレンドについて触れ、コンシューマーと企業とで用途の違いがあると述べる。企業用途では、特定領域に特化したコーパスや社内の議事録・レポートといった機密性の高い非公開データを学習に使う必要があるという。
また、同氏は、顧客が生成AIモデルを所有する重要性も指摘する。SambaNovaが提供する顧客所有モデルの場合、「組織内部のデータの正確性」「安全かつ非公開でモデルを適応」「モデルの重みの可視性」「学習データと学習方法の可視性」といった利点とともに、異なるプラットフォームへのモデル移動可能性を挙げる。
SN40Lは、クラウドでの利用は可能で、出荷は、オンプレミス対象で11月を目途に開始する予定だという。





