Googleの「Gemini」とはどんなものなのか
Geminiは、Googleの新しい強力な人工知能モデルで、テキストだけでなく画像や動画、音声も理解することができる。マルチモーダルモデルなので、数学や物理学などの分野の複雑なタスクを完了できるだけでなく、さまざまなプログラミング言語で高品質のコードを理解および生成することも可能だと説明されている。
Geminiは現在、「Google Bard」および「Pixel 8」との統合を通して利用可能だが、今後、Googleのほかのサービスにも徐々に組み込まれていく予定だ。
Alphabet傘下のDeepMindの最高経営責任者(CEO)兼共同創設者であるDennis Hassabis氏によると、「Geminiは、Google Researchの同僚たちを含むGoogleのさまざまなチームによる大規模な共同作業の成果である」という。「Geminiは最初からマルチモーダルモデルとして構築されたので、テキストやコード、音声、画像、動画など、さまざまな種類の情報を一般化してシームレスに理解したり、操作したり、組み合わせたりすることが可能だ」
Geminiは誰が開発したのか
Geminiは、Googleと親会社のAlphabetによって開発され、これまでで最も先進的なGoogleのAIモデルとしてリリースされた。DeepMindもGeminiの開発に多大な貢献をした。
Geminiには複数のバージョンがあるのか
GoogleはGeminiについて、Googleのデータセンターからモバイルデバイスまで、あらゆる場所で実行できる柔軟なモデルだと説明している。この拡張性を実現するため、Geminiは、「Gemini Nano」「Gemini Pro」「Gemini Ultra」の3種類のバージョンが用意されている。
- Gemini Nano:Gemini Nanoモデルのサイズは、スマートフォン、特にPixel 8での実行を想定して設計されている。外部サーバーに接続せずに、効率的なAI処理を必要とするデバイス上のタスク(チャットアプリケーション内での返信の提案、テキストの要約など)を実行できるように構築されている。
- Gemini Pro:Googleのデータセンターで実行されるGemini Proは、同社のAIチャットボットBardの最新バージョンでの使用を想定して設計されている。応答時間の短縮を実現するほか、複雑なクエリーを理解することもできる。
- Gemini Ultra:Googleは、まだ広く公開されてはいないGemini Ultraについて、最も高性能のモデルと説明している。同社によると、Gemini Ultraは、「大規模言語モデル(LLM)の研究および開発で広く使用されている32の学術ベンチマークのうち30で、現在の最先端の結果」を上回ったという。Gemini Ultraは、極めて複雑なタスク向けに設計されており、現在のテスト段階が終了した後でリリースされる予定だ。
どうすればGeminiにアクセスできるのか
Geminiは現在、Pixel 8スマートフォン(Gemini Nano)とBardチャットボット(Gemini Pro)で利用できる。Googleは今後、検索や広告、「Chrome」、そのほかのサービスにGeminiを統合していく計画だ。
開発者と企業顧客は、米国時間12月13日より、Googleの「AI Studio」と「Google Cloud Vertex AI」のGemini APIを通して、Gemini Proにアクセスできるようになる。「Android」開発者は、早期プレビューにサインアップすると、「AI Core」を通してGemini Nanoにアクセスできるようになる。
GeminiはGPT-4などのほかのAIモデルとどこが違うのか
Googleの新しいGeminiモデルは、これまでで最も大規模かつ先進的なAIモデルの1つであるようだが、Ultraモデルがリリースされるまで、それが事実なのかどうかは確かめようがない。現在、さまざまなAIチャットボットで使用されているほかの人気モデルと比べて、Geminiが際立っているのは、最初からマルチモーダルモデルとして構築されたことだ。「GPT-4」など、ほかのモデルはプラグインや統合を通して、真のマルチモーダル性を獲得している。
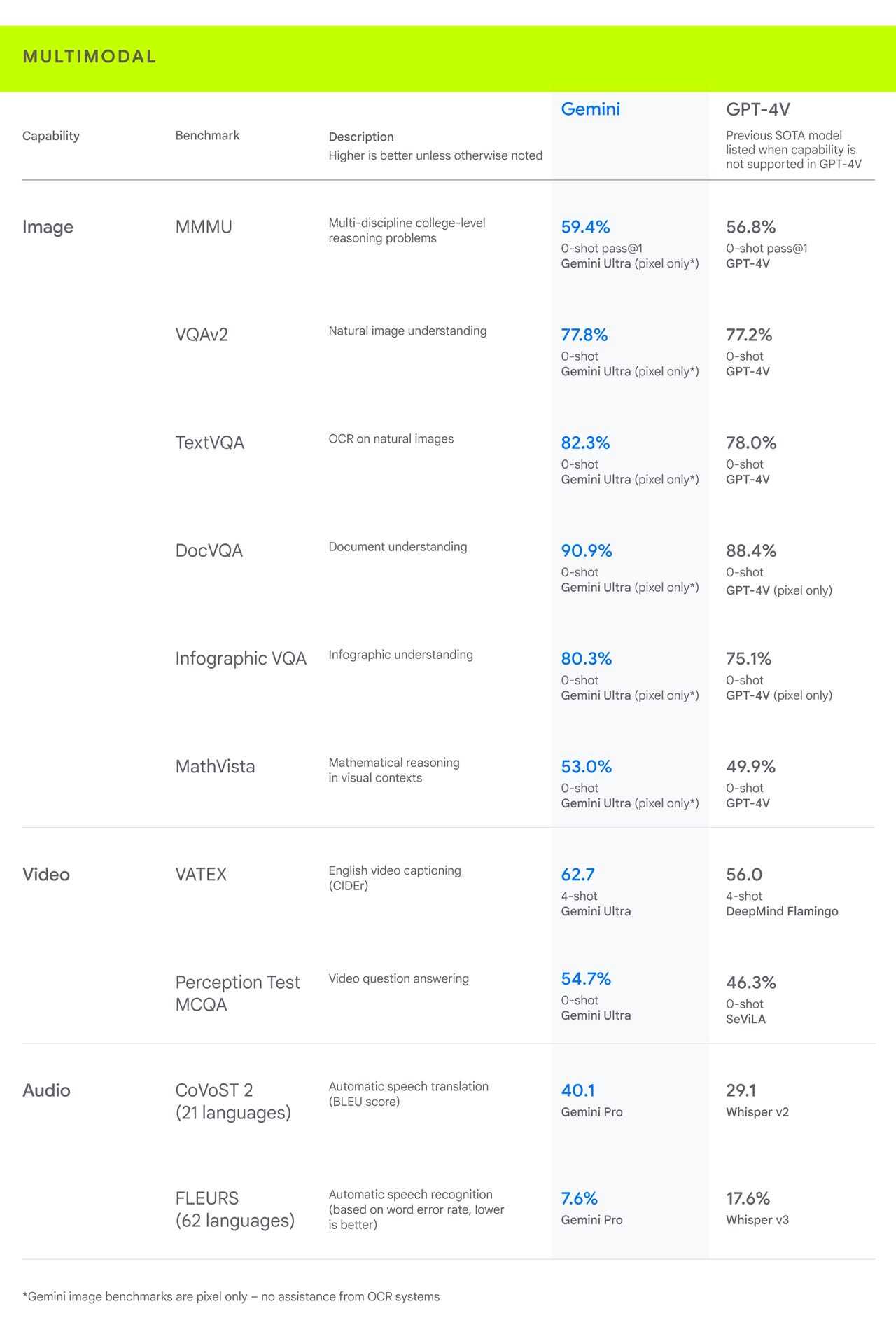
Googleが公開した上記の表では、Gemini UltraとOpenAIのGPT-4、Gemini Proと「Whisper」をそれぞれ比較した結果がまとめられている。
提供:Google/ZDNET
主にテキストベースのモデルであるGPT-4と比較すると、Geminiはマルチモーダルタスクを簡単にネイティブで実行できる。GPT-4は、コンテンツ作成や複雑なテキスト分析などの言語関連タスクをネイティブで処理するのが得意だが、画像分析とウェブアクセスにはOpenAIのプラグインを使用し、画像の生成と音声の処理には、それぞれ「DALL-E 3」と「Whisper」を利用する。
GoogleのGeminiは、現在利用可能なほかのモデルよりも製品に重点を置いているようだ。BardとPixel 8の両方に搭載されているように、Geminiは同社のエコシステムにすでに統合されているか、あるいは、今後統合される予定だ。GPT-4やMetaの「Llama」など、ほかのモデルは、よりサービス指向であり、さまざまなサードパーティーのアプリケーションやツール、サービスの開発者に公開されている。
提供:Maria Diaz/ZDNET
この記事は海外Red Ventures発の記事を朝日インタラクティブが日本向けに編集したものです。





