たとえば、男女で男性40%対女性60%の全件データは、ランダムに抽出すると、サンプルデータでも同様にほぼ40%対60%となりますが、男性を多く抽出するというように、そこに恣意性が入りますと、そのサンプルデータは全件データとは異質なデータとなっていることにご注意ください。図1は、ランダム・サンプリング(1.1)と恣意的なサンプリング(1.2)を対比させたイメージ図です。
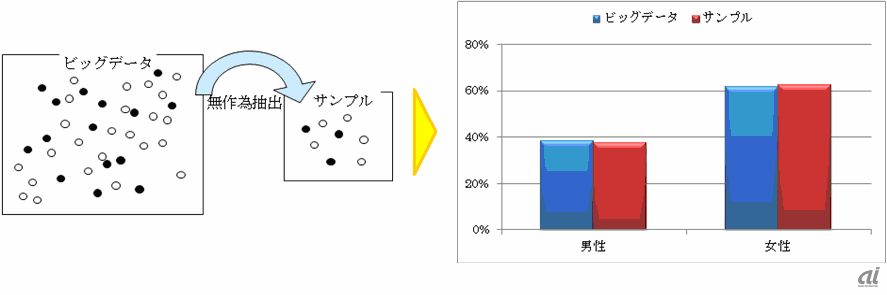
図1.ビッグデータからサンプルデータの抽出イメージ ※●男性、○女性1.1_ランダム・サンプリング(=無作為抽出)
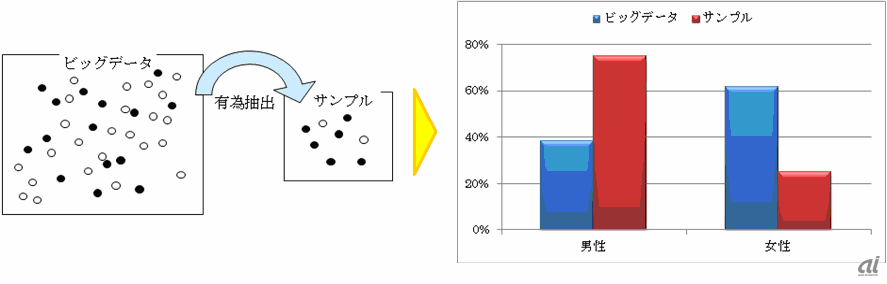
1.2_恣意的なサンプリング(=有為抽出)
データサイエンティストとしては、できるだけ多くの情報量を用い、誤差を小さくしたいところですが、マーケターとしては、ROIに見合うところで扱うデータ量に見切りをつけたい、という2つの相反するニーズのせめぎ合いの中で、実際は意思決定していくことになります。
統計学は誤差の学問であるともいわれます。ある程度間違うリスク(=誤差)を許容しながら、分析から得られる恩恵が、掛けるコストに見合う形でデータを活用したいというビジネスニーズに、ランダム・サンプリングという方法は、大いに役に立つでしょう。私自身、SUUMOの分析業務を行う際にデータ全件を分析しなければいけない状況はそれほど多くはありません。時間とコストの節約のためにもランダム・サンプリングを適宜活用することを推奨します。
これら全件データとサンプルデータとの関係性や法則をより詳しくお知りになりたい方は、「大数の法則」や「中心極限定理」などが記述されている統計学の入門書をご参照ください。