
機械学習のキーとなるアルゴリズムは、MED(最大エントロピー原理)と呼んでいる第三世代の機械学習アルゴリズムです。従来のアルゴリズムと違って、IPアドレスやURL、ファイルなどさまざまな複数のデータを「n次元」という形で同時に分析することが可能です。また、クラウドのパワーを使うことでエラー率の低く精度の高い、しかも内容の深い情報の提供を可能にしています。
Bright CloudはさまざまなベンダーにOEMで提供しており、実は使っているという企業も多いのではないでしょうか。
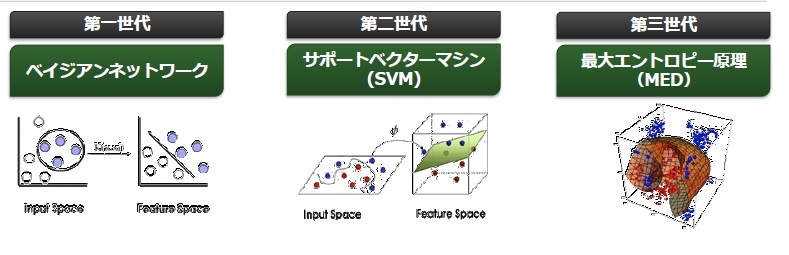
機械学習のアルゴリズムの進化
他のベンダーが防御よりも侵入されてからの駆逐なのに対して、Bright Cloudでは精度の高い防御が可能と言えます。とはいえ100%の防御は難しいのですが、98%以上の精度はあります。残りの2%程度は新しい脅威です。そこで、この2%には人手を使って、脅威を分析するエンジンの教育を担当させています。それにより、機械学習の精度をさらに高めています。なお、人による予測もこの2%に含まれます。
――日本でも米国でもヒューマンエラーによる情報漏えいが引き続き発生している。これを防止するためにはどのようなガバナンスが必要か。例えば年金機構での情報漏えいは、どのような対応をしていれば防げたか。
年金機構の情報漏えいは、ウイルス感染が原因でした。その感染ルートには5つが考えられます。それは、「保護されていない状態でネットワーク接続されていること」「インストールされるべきではないものがインストールされること」「USBメモリのような接続すべきではない外部ドライブを接続すること」「不適切なリンクをクリックすること」「パッチの適用が不十分であること」です。
そこでわれわれセキュリティベンダーは、ユーザーの行動を理解する必要がでてきます。いくら制止したとしても、ユーザーがそれらの行動を取れば感染してしまいます。その行動を取る理由は「面白そうだ」とか「面倒だ」というのがあると思われますが、対策するのであれば「自動的に阻止する」ことが必要になるかと思います。
私は1985年から30年にわたってセキュリティに携わっておりますが、その中でユーザーの振るまいにすべて対応するのは難しいということはよく理解しています。そこで感じたことは、ユーザーの選択に任せていては不十分ですので、確実に守るためには自動的に実施する必要があるいうことです。
それを実現するためにはクラウドによる機械学習は不可欠です。それによってユーザーがやろうとしていることが危険なことであれば、きちんと阻止しなければいけません。また、情報漏えいには2つの側面があります。ひとつは外部からのサイバー攻撃。もうひとつはユーザーによる不適切な操作です。この2つが組み合わさると情報漏えいが発生します。そのため、ユーザーによる不適切な操作は確実に止めなくてはいけません。
われわれはこの業界内で、高い顧客満足度を得ていると自負していますが、その理由は2つあります。ひとつは、ユーザーに対して「これはいけない、これは危険だ」と言い続けるのではなく、あくまでもユーザーが危険な行為をしようとするときだけ、それを阻止できるということ。
もうひとつは、すべてのものが軽いということです。これまでのセキュリティはいろいろなものをPCにインストールするので、定義ファイルの更新、アクセス防止、ウィルススキャンも重くなっていました。Webrootはすべてをクラウド上に置いているために、動作はとても軽くなります。PCにインストールされるファイルは700Kバイトだけです。この2点が高い顧客満足度を得ている理由です。





