富士通研究所は、高精細・大容量な映像データを人工知能(AI)が認識できる必要最小限のサイズまで高圧縮する技術を開発した。
同社では、工場で梱包作業を行っている複数作業員の様子を4Kの高精細カメラで撮影した映像に今回開発した技術を適用し、認識精度が劣化することなくデータサイズを10分の1に削減できることを確認した。
第5世代移動通信システム(5G)の普及に伴い、高性能カメラで撮影した高精細な映像データや街頭、製造ラインなどに設置された多数のカメラ映像などが爆発的に増加すると予測されている。映像を解析するAI手法としてはディープラーニングが多用されるが、処理が膨大なため、端末側のエッジサーバーだけで大規模な映像を解析する場合、エッジサーバーの増強などによる計算処理能力の確保が必要となる。解析には、クラウドと連携した処理が有効だが、映像データはサイズが大きいため、ネットワーク帯域がひっ迫しないように、全ての映像データを品質を落とさずにクラウドへ送信できる高圧縮技術が求められていた。
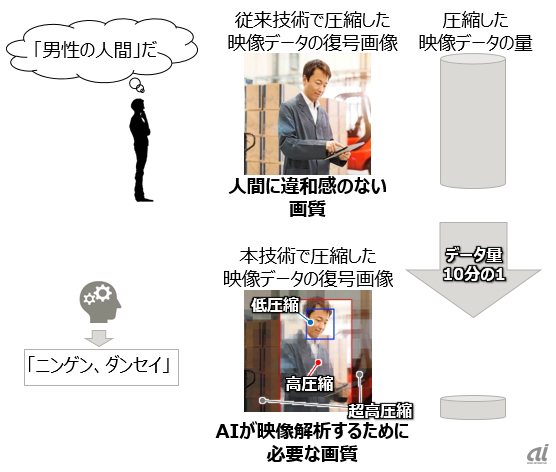
人間ではなくAIが認識できる画質のイメージ(出典:富士通研究所)
今回開発した技術は、AIが判断材料として認識している対象物の領域を自動的に解析し、領域ごとにAIが認識できる必要最低限な画質で圧縮を行う。これによりAIでの認識精度を維持したまま、従来の人間による視認を目的とした圧縮技術に比べて映像データのサイズを大幅に削減できる。
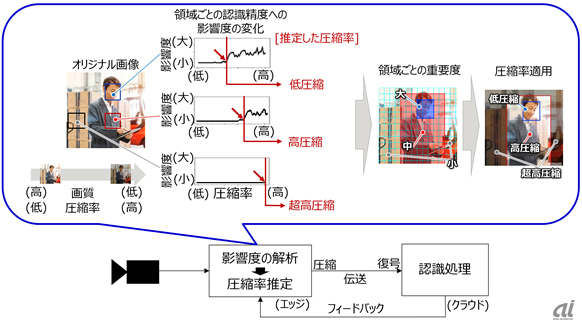
AIの認識精度を元に圧縮率を推定(出典:富士通研究所)
AIの認識精度に影響しない圧縮率の自動推定では、画像全体の圧縮率を変えて画質を変化させ、その圧縮率を変化させたときの認識結果への影響度を格子状に区切った画像領域ごとに集計する。これにより、AIが認識する過程における特徴の重要度合いを全ての領域ごとに判定できるようになる。そして、その各々の領域において認識精度を急激に劣化させる直前の圧縮率を認識精度に影響しない圧縮率として推定する。さらに、連続する画像におけるAIの認識結果をフィードバックして必要最小限まで圧縮率を高めることで、認識精度を維持した状態で画像の高圧縮を実現する。





