
はじめに
ITサービスのインフラ運用・改善といった観点から「Site Reliability Engineering(SRE)」という言葉を耳にすることが増えてきました。本連載は、多くの企業にSREサービスを提供している立場から、「SREとは何か?」「DevOpsやインフラエンジニアと何が違うか?」「どのような場面でSREが必要になるか?」といった点について解説します。また、SREを始めるに当たっての実践方法などについても紹介します。
Googleで提唱されたSRE
SREとは、一体どういったものなのでしょうか。
この言葉の生みの親であるGoogle のテクニカルオペレーションを統括するBenjamin Treynor Sloss氏は、以下のように答えています。
What exactly is Site Reliability Engineering, as it has come to be defined at Google? My explanation is simple: SRE is what happens when you ask a software engineer to design an operations team. (引用元:Lessons Learned from Other Industries)
和訳(手塚):シンプルに言えば、GoogleにとってSREとは、ソフトウェアエンジニアに運用チームの設計を依頼した時にでき上がるものです。
この言葉によって、SREにおいてソフトウェアエンジニアリングという手法が核になるというのが分かると思います。
しかし、今一度よく考えると、これまでの組織や運用を考えた際に、ソフトウェアエンジニアが運用を担当して設計するというのは多かれ少なかれ役割違いに思えます。ただ、この違和感こそが既存の運用との大きな違いであり、SREがSREたるゆえんでもあるのです。
SREは「トラディショナルな」運用・保守チームと何が異なる?
これまでの運用・保守と、SREで用いられる手法の間にはどのような違いがあるのでしょうか。参考までに比較すると以下のようになります。
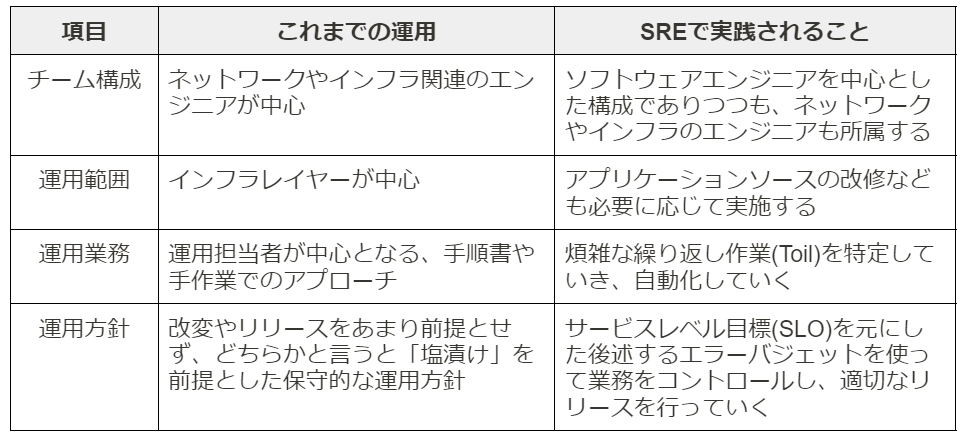
組織によって異なる部分も大いにあるため一概には言えませんが、これまでの運用チームは、どちらかと言えば「保守的な」アプローチとして存在しており、いかに「システムを維持し、守っていくか」というところに主眼が置かれているのが分かります。
対してSREは、システムの信頼性を担保するためのアプローチを十分に行いつつも、繰り返しの作業に対しては自動化を行ったり、SLOを元にしてエラーバジェットによる業務ハンドリングを通じて適切なリリースエンジニアリングを行うなど、「変化しながら、攻めていく」アプローチも併せて行っていきます。
以上のように、根本的な考え方を含めてSREは、「トラディショナルな」運用・保守チームの延長線上に存在しているわけではないことが分かります。あくまで、ソフトウェアエンジニアリングを通じて運用業務を遂行していくという観点においてSREは成立するものであると考えられます。
ビジネスの状況が変化するスピードが加速している昨今は、こういった「システムを維持し、守っていく」アプローチよりも、「変化しながら、攻めていく」アプローチが求められているのが自明でと言えるでしょう。




