日本IBMは9月4日、同社のアナリティクス事業に関する報道機関向けの説明会を開き、日本企業でデータ分析から得た知見を事業に活用するための基盤整備が遅れていると指摘した。説明会ではその普及を支援するという製品群やサービスなどの施策を訴求した。

日本IBM 取締役専務執行役員 IBMクラウド事業本部長の三澤智光氏
会見した取締役専務執行役員 IBMクラウド事業本部長の三澤智光氏は、「顧客企業の多くが本格的な顧客データ分析や人工知能(AI)への取り組みを加速させたいとしているものの、うまくいかないとの相談が多い」と話す。同氏によれば、IBMのコグニティブコンピューティング技術「Watson」の企業導入プロジェクトでは、すぐに分析などへ利用できる企業データは3割以下にとどまるのが現状という。
大半のデータは、最終的には利用可能であるものの、そもそも取得に手間がかかるものだといい、三澤氏は、データ活用以前の段階で“壁”に突き当たっているとした。説明会の趣旨は、企業がこうした課題を乗り越え、データ活用を通じて収益化を図るための基盤の整備を促すという点だ。
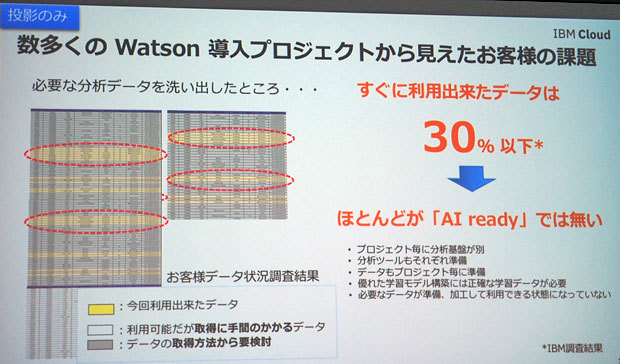
Watson導入プロジェクトでは活用できるデータが3割以下という実態があるという
三澤氏は、企業がデータを活用する目的を大きく2つ挙げる。1つは、IoTのセンサデータなどを生産性の改善や向上などに使ったり、あるいは顧客データなどの詳細な分析を通じて販売を強化したりするような間接的な利用という。もう1つは、データを外部企業に販売するような直接的な利用となる。同氏は、目的がいずれかであっても実現までには、(1)どこでも・だれもがデータを利用できること、(2)誰もがデータ提供者となり、APIを介したエコシステムを実現すること――という段階を経る必要があると述べた。
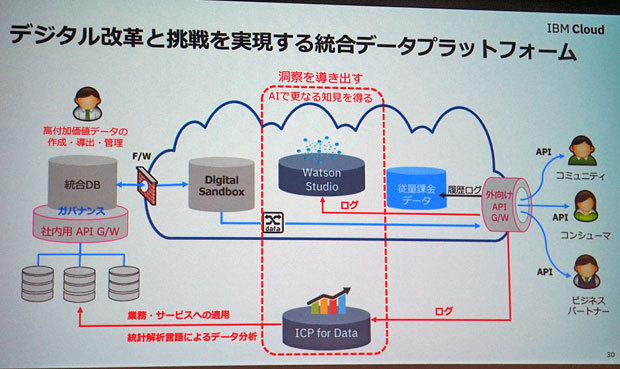
基盤の観点から(1)では、同社が「Enterprise Catalog」と呼ぶコンセプトに基づく仕組みを説明した。構造化データと非構造化データの両方を取り込み、自動分類されたメタデータを利用して各種データの検索、用語辞書、ルール、ガバナンス、共有といったデータの利用のためのカタログを管理する基盤となる。これを開発者やデータサイエンティスト、事業部担当者などのあらゆるユーザーが必要に応じて機械学習や分析などツールに取り込み、利用できるようにするとしている。

日本IBMが「Enterprise Catalog」と呼ぶコンセプト。いわゆる“データレイク”に当たる
加えて三澤氏は、この基盤では概念実証でのクラウド利用と、データセキュリティなどの点でオンプレミスでの利用に対応することが求められるとし、製品としてフルマネージド型のパブリッククラウドサービスで提供する「IBM Watson Studio」、オンプレミス向けの「IBM Cloud Private for Data」を挙げた。両製品の概要は7月の事業説明会でも触れたが、機械学習モデルやメタデータ、データ管理などの機能をパッケージ化し、動作環境にKubernetesやDockerコンテナを使用することで、オンプレミスあるいはIBM Cloud、Amazon Web Services(AWS)、Microsoft Azure、Google Cloud Platformなどのさまざまな環境で柔軟に展開できると強調する。
一方、収益化の観点では上述の基盤の構築や利用を支援するというコンサルティングサービス「DataFirst Method」や、約100人の同社のデータサイエンティストが分析モデルの構築、顧客社内での人材育成、コミュニティー活動の支援を提供する「Data Science Elite Team」、データ活用関連ソリューションを提供するパートナープログラム「IBM Cloud Partner League for Data」を立ち上げ、国内での展開を本格化させる。
データ活用の収益化イメージの一例。ここでも基盤が中核を成すという
三澤氏は、競合ベンダーもさまざまなデータアナリティクスや人工知能(AI)の機械学習などのソリューションを展開するようになり、データ活用が企業にとってより身近になっているとした。ただ、その機運の盛り上がりに対して競合ソリューションの多くは汎用的であり、容易に使い始められるものの、まだ本格利用できる水準には達していないと自身の見解を示し、同社が競合より早い段階から企業の本格利用に対応し得るソリューションを提供している点が優位性だと強調した。