データサイエンスやアナリティクスの重要性が高まり、それらの大衆化も進んでいる中、仮説を検証したり、知見を引き出したりするのに適したデータを見つけることは、ますます重要になっている。
かつては研究者やギークだけのものだった領域が、今でははさまざまなプロフェッショナルや組織、ツールも扱うものになっており、そこに参加する人の幅も広がり続けている。もちろん、単に自分の関心のために調べる人たちもいる。
よく組織化された、豊富なデータを持っている組織にも、所有しているもの以外のデータを利用しなければならない場合がある。典型的な例は、天候や環境に関するデータだろう。
例えば、農業に関するデータと気象現象の相関を調べて収穫量を予測したい場合や、過去に起こった現象に対する天候の影響を調べたい場合を考えてみてほしい。普通の組織には、その種の天候に関する時系列データを蓄積したり、吟味したりすることは難しいが、米海洋大気庁(NOAA)やNASAのような組織の手元にはデータが揃っている可能性が高い。
こういった組織は、データを吟味し、専用のデータ公開ポータルで定期的に公開している。このため、普段からその種のデータを必要としている人なら、おそらくそれらのポータルでデータを見つける作業には慣れているだろう。それでも、NOAAとNASAの両方のサイトをチェックする必要があるし、他にも情報源があるかもしれない。
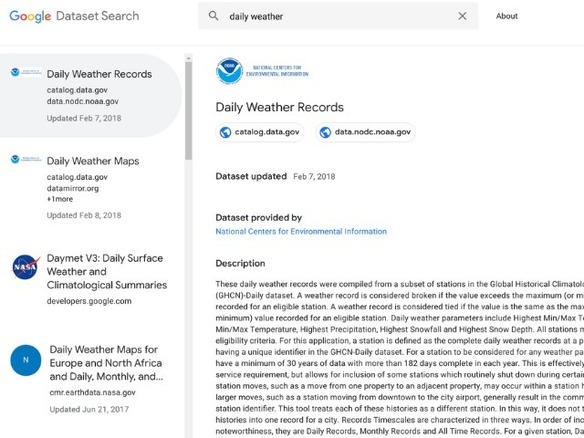
天候以外のデータも必要になれば、作業はますます大変になる。適切な情報提供者を見つけ、そこで適切なデータを見つけなければならない。ウェブを「ググる」ときのように、1つの検索インターフェースで、世の中に出ているあらゆるデータを探すことができれば、事態は簡単になるはずだと思ったことがある人もいるだろう。その期待に応えて登場したのが、データを「ググる」感覚で利用できる「Google Dataset Search」だ。
Schema.org、メタデータ、そしてセマンティクス
もちろんこれは、ただ突然可能になったわけではない。Googleはずっと以前から、構造化データとセマンティクスの問題に熱心に取り組んできた。過去のMetaweb買収による知識グラフの取り込みや、schema.orgの構造化メタデータのサポートなどは、今回の取り組みにつながっている。
SEOを手がけている人であれば、それらの取り組みによってGoogleの検索品質がいかに変わったか、コンテンツ提供者が利用できる選択肢がどれだけ広がったかを知っているはずだ。schema.orgのボキャブラリを使ってコンテンツをマークアップできる機能は、(それによってウェブの検索結果でレーティングなどの情報が見られるようになったことはさておき)現在実現されている、セマンティックウェブの分野で言う大規模な「データのウェブ」にもっとも近いものだと言えるだろう。
これと同じ仕組みが、データセットの検索にも使われている。GoogleのNatasha Noy氏とDan Brickley氏が2017年の初めに発表した研究ノートには、その開発過程が説明されている(この2人は、セマンティックウェブのコミュニティでも有名な人物だ)。このノートでは課題が説明され、どのような行動を取るべきかが示されている。その鍵となるのは、やはりschema.orgだ。
提供:Go Live UK




