
はじめに
第1回に続き、第2回目では、アナリティクスを始めるにあたって仮説構築の重要性と、それをサポートするアーキテクチャの要素である「データ収集」と「データ蓄積」に求められる柔軟性について、解説し、それらのOSSでの実装例を紹介する。
仮説構築の重要性
アナリティクスは、前回述べた包括的なアーキテクチャにおける論理的思考の最初のステップ「事象の観察」、分析作業としての「データ収集」から始まるが、やみくもに観察と収集をするということでは、余分なデータを苦労して集たりと無駄が多くなる。その先のプロセスである「構造化」を思い描き、予め仮説を立てておくことが重要である(図1)
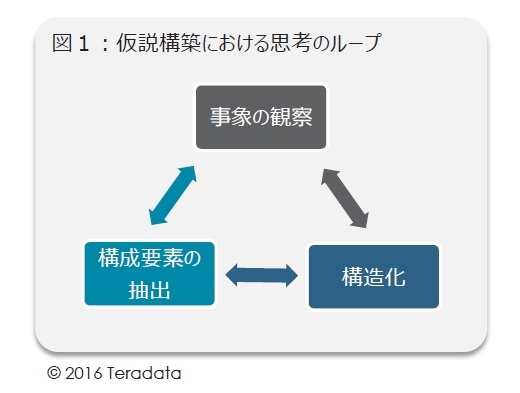
図1
つまり、解決すべき問題、課題を明らかにし、その背景にある構造化仮説から、何を観察すべきなのかをある程度絞りこむことから始めることが肝心である。まさに「ビジネス感覚」が要求されるところである。
アナリティクスにおけるディスカバリー
アナリティクスにおいて、「ディスカバリー」(探索と発見)という言葉もビッグデータの時流の中で使われることがよくあるが、何をディスカバーしているのか。
指数関数的に増えていく構造化データ、非構造化データを、闇雲に探索すれば、何かが見つかるのだろうか。答えは「NO」である。コンサルティング業界では、企業が抱える問題に対して「筋の良い」仮説を作り出し、短時間で顧客の抱える課題を解決し、実行をサポートすることが、価値のあるコンサルタントとして評価されている。
同様にアナリティクスにおいても、ディスカバーしたいものとは、「筋の良い」仮説なのである。つまりこれは、事象をよく表現できる、予測精度の高い「構造」を見つけ出すことである。
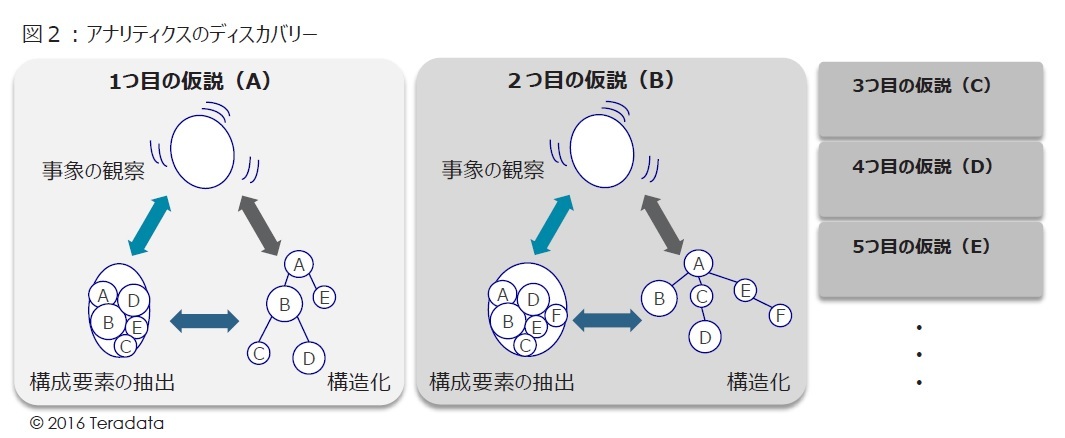
ディスカバリーの例(図2)
アナリティクスにおけるディスカバリーとは、構成要素と構造化の見直し作業の繰り返しと言える。
1つ目の仮説(A)は、構成要素は5つであったが、仮説を見直すことで、2つ目の仮説(B)は、構成要素は6つとなり、構造も変化する。またシミュレーションを実施した際に全体の挙動も変化するかもしれない。
このように仮説のバリエーションを増やしながら、観察事象の再現と構造化の精度を上げていくことが、アナリティクスにおけるディスカバリーである。
アナリティクスとアーキテクチャの関係
ビッグデータの本質は「アナリティクス」の繰り返し、という本稿第1回のテーマにもあるように、シンプルに考えれば、それは、仮説構築と検証を繰り返すことである。論理的思考の検証としての分析作業としては、まずは「データ収集」し「データを蓄積」することから始まる。
それに続く作業として、「データ整理・加工」を通して、まさに構成要素の妥当性の確認や「要素の関係性探索」をして「構造化」し、その構造化されたモデルに対して「シミュレーション」を行う。
そして最後に、シミュレーションの結果から将来を予測し、今後の施策やアクションを立案していくと言う「見せる化、意味合い抽出」となる。これらのアナリティクスの作業プロセスとそれに対応するアーキテクチャが重要であり、包括的に全体設計を見通し、さまざまなソリューションを組合せて行かねば、アナリティクス自体が最適化されない。
包括的なアーキテクチャにおける「データ収集」と「データ蓄積」
上記のアナリティクスとアーキテクチャの関係から見えてきたものとして、ビッグデータによって、検討可能な構成要素(取得できるデータの種類)のバリエーションが爆発的に増えているため、考え得る仮説の数も当然に増えている。そのため、より速く効率的に仮説検証を繰り返す必要がある。
特にデータ収集・蓄積に関しては、以下のような場合にダイナミックな要求が発生しており、フレキシブルな対応を迫られている。
- Fail Fastの考え方を取り入れ、アジャイル手法への対応が必要
- 仮説構築と検証を繰り返す毎に、新たなデータを取得蓄積することが必要
- 新たなデータが発生し蓄積量も増加するので、スケーラブルなシステムが必要
- 現在のシステム環境で定義されていないタイプのデータ型への柔軟な対応
- データの鮮度、リアルタイム性が要求される予測モデル構築など
実際に、データソースの追加(もしくは削除)が発生した場合、さまざまな変更がシステム基盤やプロセスの中で散見され、実際のところ現場ではその対応の半分を諦めているのが実状だろう。
システム間でデータ転送するために、詳細なインターフェースを定義し、ETLを実装し続けている現状からは考えられない発想の転換を求められており、データ取得・蓄積・加工に関する機能をどこで実現するかの議論がより深まりそうだ。
特にIoTに至っては、さまざまなセンサから発生するデータが新たなデータタイプをもたらすことも頻繁にあり、データベースの構造にも影響することがある。さらに、最近ではアナリティクスの分野でもリアルタイム処理もしくはニアリアルタイム処理を望む声も大きくなってきており、そのような場合にもデータをどのように蓄積していくかが課題になる。





