NECは8月5日、多種多様なデータの意味を推定する人工知能(AI)技術「データ意味理解技術」を開発したと発表した。
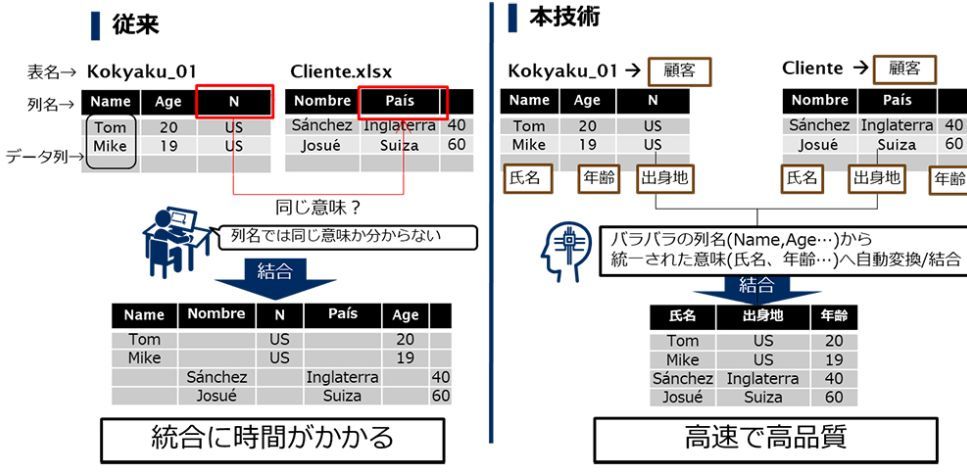
この技術は、専門家が時間をかけて行っていた、分野や業種の異なる複数の表データの統合作業を、高速かつ高品質に自動化する目的で開発された。近年、データ流通基盤や情報銀行など、データを部門間、企業間、さらには業界間で共有し統合することで、これまでにない横断的な分析を行う取り組みが活発になっているが、これまではデータ管理の専門家が膨大な量の表データを精査し、何のための表データか、その表データの各行や列が何を表しているかを見極め、人手で統合を行っていた。
例えば、表データにおける数値データ列に「29、24、23」がある場合、単独では「年齢」や「気温」などさまざまな意味が想起できる。しかし、同じ表データに「氏名」の項目が含まれていれば、その数値は「気温」データではなく、より関係性の強い「年齢」データであると推定できる。同技術では、こうした推定をAIで自動的に行える。
同技術をオープンデータに適用したところ、専門家が30日かけていたデータ統合作業を、わずか1時間で同等品質にて実現することを確認できた。
新技術の特長
同技術では、バラバラの列名から自動変換しデータを結合することが可能になる。元々付与されている表名や列名を手がかりとするのではなく、各データ列の数値分布の統計的な傾向を手がかりとする。事前にナレッジグラフ内の各単語について、その単語と共起する数値を収集し、単語の数値分布を含む独自のナレッジグラフを構築する。そのうえで数値データ列から数値の出現頻度の分布傾向を示す特徴量を算出し、ナレッジグラフ上の単語ごとの数値分布と比較することで、列名のないデータについても、「売上高」といった意味の推定が可能になる。
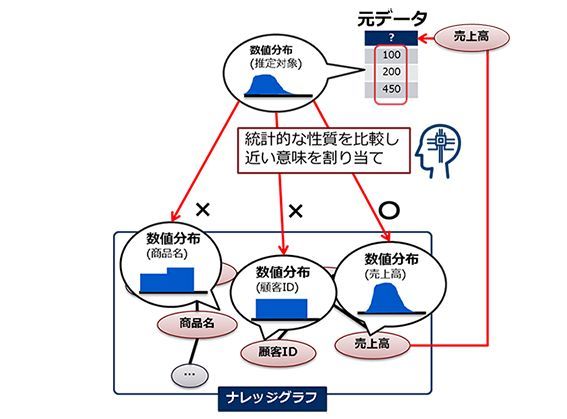
特徴量に基づいたナレッジグラフとのひも付け(出典:NEC、以下同)
また「29、24、23」など数値データ列では、それ単独では「年齢」や「気温」などさまざまな意味が当てはまるため正しい意味の推定は困難となる。今回開発した技術は、「推定対象のデータ列の意味候補」と「同一表データにある他のデータ列の意味」の共起関係をナレッジグラフ上のネットワーク距離(=データの意味間の共起関係の強度)を活用し推定することで、高い精度での推定を実現する。例えばあるデータ列について、同じ表データに「氏名」の項目が含まれていれば、ナレッジグラフから、「気温」データではなく、より関係性の強い「年齢」データであることを推定する。
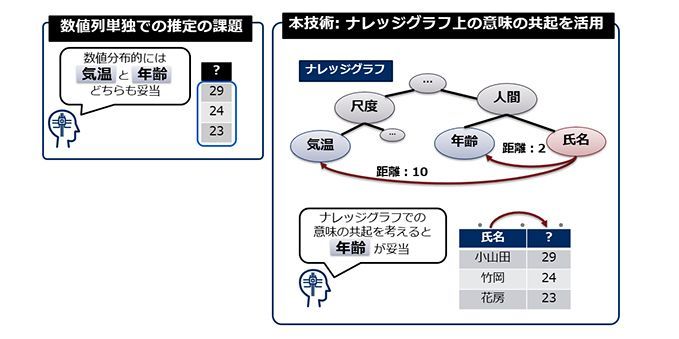
ナレッジグラフ上のネットワーク距離を活用した推定