データではない、知こそが宝である
次の日である、新聞を眺めているとこんなニュースが目に飛び込んだ。いまでは普通の言葉と成り果てた機械学習についてのニュースである。
機械学習でカンニングの検出に成功したそうで、面白いことを考える人もいるものだなと、その瞬間はそう思う程度だった。答案データを出力として、その人がどれだけの能力があり、そして問いた問題がどれだけの難しさがあったのか、さらには他の人の回答結果が反映されているということを入力にすれば、カンニングの推定はできそうだ。なんだ、簡単じゃないか。彼はもはや機械学習のことならすぐに想像できるようになったため、自分の理解を超えるものではないとして軽い気持ちでその新聞をたたんで仕事に向かった。
昨日の上司の残念そうな顔を思い出す。機械に全て任せているなんて言ったら怒られるかな。正直に言ってしまえば意外に許されるかもしれないな。そんなことを悩みながら、ディスプレイをぼんやりと眺めている。
「あ、もしかしたら。あの人事評価システムは、どんな比率で、どの入力を大事にしているかを見れば、上司の質問に答えられたかもしれないな」
そう思い立ってPCのキーボードをたたいて眺めてみると、驚愕の事実に気付く。なんと全ての入力をそれなりに意識して、出力たる評価値を計算していることが分かったのだ。その意識する重みの値を見ると無味乾燥に数値が並んでいるだけで、何が重要なのかよくわからない。
確かに人の評価というのは微妙なものだ。色々な要素を考慮するのは真実である。しかし、こんなにも微妙にさまざま入力を意識するのか。そこではっと思い出す。カンニングの検出のニュースである。その場合も出て来た出力結果である答案をうまく説明するために、能力や難易度以外の第三者の存在を入力としたら、それらについても微妙に考慮してしまい、誰がカンニングをしたのかなど断定することはできないではないか。
あわててウェブ版のあのニュースの記事を読む。そこで目に飛び込んだものは「スパース性」である。
機械は賢く微妙なところもうまく計算をして、なんとかして入力と出力の関係を絶妙に「学習」してくれる。しかし待ってくれ、本当にその要素は必要だったのだろうか。それに答えてくれるのが「スパース性」である。どの要素が必要か不必要か、自動的に判別しながら、データをうまく説明するための入力を絞り出してくれるというのだ。
彼は早速スパース性について検索しながら、自分のプログラムに組み込むことにした。軟判定しきい値関数など難しいところもあったが、単純な方法をカンニングの検出については行っていることがわかった。
必要のなさそうな要素、つまりカンニングをしていなさそうな第三者からの影響は従来の計算方法でも、カンニングをしていなさそうだよといわんばかりにその入力を意識する重みが小さいことに気付いた。それを大胆にも切り捨てる。
これを「デシメーションアルゴリズム」というそうだ。そして切り捨てた入力は、今後一切意識せずに、再び学習を実施するという方法を採用していた。これを続けて行くと次々に必要のない要素を切り捨てて、残ったいくつかの重要な入力だけが残されるというわけだ(図4)。
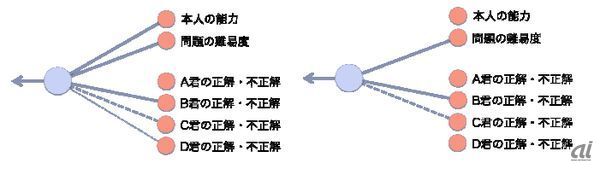
図4:デシメーションアルゴリズムの様子 左図では点線で表された弱い関係を右図のようにバッサリと切る
そのときに全部切り捨てることのないように、データをどれだけうまく説明しているかという数値を見ているのが重要なようだ。その数値が突然減少したら、うまくデータを説明できなくなっているのだ。つまり重要な要素を切り捨ててしまったとして、戻す必要がある。
そして、「これだ!」という要素にたどり着いたとき、おもわず、声が出た。叫んだ彼に何人かの同僚が視線をやる。上司も気付いたようだ。





