
機械学習の本を眺めてみよう
これまで、少ないデータから意味を見出すための方法論「スパースモデリング」(スパース性)の概要や実践方法について触れてきたが、連載第3回目では機械学習におけるスパース性の利用を考えてみる。機械学習というと言葉自体は耳にしたことがある読者も大勢いるだろう。基本的には、「目の前にあるデータに潜む関係性を機械に自動的に発見してもらうこと」が機械学習の意味だ。例えば前回のデータ点に直線や曲線を当てはめるというのも機械学習のできることの1つの例だ。
さて、その機械学習とは何か、本屋さんで関連書籍に目を通してみることにした、ある1人の会社員の物語から、機械学習とスパース性の関係を考えてみよう。
彼は簡単なプログラミングの経験があるが、現在は人事部に所属しており、面接官を務めている。入社を希望して目を輝かせては、考えてきた回答、とっさに出てきた本音を聞きながら、目の前の学生や中途採用予定の人材の採用を懸命に考えている。しかしどうもこの作業がしんどい。
どうにかして効率的に楽に人材を採用できないだろうかと考え、最近雑誌で読んだ「機械学習」というキーワードを調べてみた。本屋で手に取った機械学習がタイトルに入った専門書を読むと、数式の嵐。よくわからない。でも決まって丸と線がごちゃごちゃつながった図がある。これは何だろうか。

図1:よくわからない機械学習の書籍にある図
どうもこれを読み進めるだけではなく、検索しながら勉強を進めて行くと、これはデータを機械がどう解釈していくかという関係を抽象的に表した図であるようだ。本当にそれが正しいかではなく、こうやってデータを理解させるというものかな、という印象を持った。
右側の入力部分にデータを入力させたとき、左側の矢印から、このデータはどんなものだったと機械の判定を出力してもらう。そういう宣言だ。彼は数日間ほど、機械学習の勉強に没頭した。
機械に学ばせる
前回と同様に、ばねにおもりをつけたときに、ばねの長さはどうなるかという予測を、機械にしてもらうという単純な例を通して、機械学習の触りを紹介しよう。ばねの長さを決めるには、おもりの個数、元々の長さを入力として、ばねの長さが出力という格好(図2)がよいだろう。
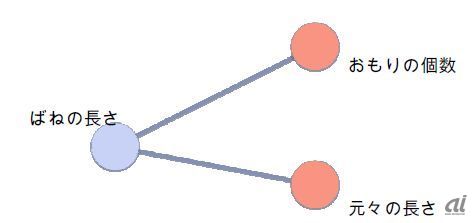
図2:よくわからない機械学習の書籍にある図
ここで気になるのは、線である。ばねの長さに対して、元々の長さとおもりの個数がどれだけ強い影響があるのか、ということを機械学習では、あらかじめ「学習」させておく。そのため、いくつかの実験結果を入力と出力に入れたときに、そのどれにも適合するようにするということで「学習」される。
ちょうどこれは前回のデータ点に直線を合わせたときと同じように、最も適切なものを選んでもらおう。どのデータともあまりずれないように。
こうすることにより、機械はそのばねの「過去」の経験を踏襲した予測が可能となる。おもりが1個、2個、3個のときの結果から、4個のせた場合、5個のせた場合についても機械なりに予測する。
しかしその結果はいつまでも通用することはない、それまでに学んだことのない不測の事態には対応しきれない。例えばばねはあまりに強い力で引っ張ると伸びきってしまう。予測されるよりも間抜けな姿になってしまうだろう。あくまで「学習」なので、過去になかったことをうまく予言することはできない。
なるほど機械学習、使えそうだ。夜遅くまで勉強をした彼はある決意をする。機械学習を本格的に運用して、自分の会社に貢献することを目指してみよう。





