大日本印刷(DNP)は12月14日、ドキュメントデータのコンテンツを解析、整形して、生成AIに学習、参照させることができる独自技術を開発したと発表した。これにより、生成AIの回答精度を向上させることができるとしている。
開発した技術は、PDFなどのドキュメントに含まれるテキストや画像、表組みなどのコンテンツを独自のAIモデルでタイトルや本文、画像、表の内容、キャプションなどの要素ごとに分割し、生成AIが学習、参照しやすいデータ形式に整形する。機械処理で行うため、大量のドキュメントを高速処理できるという。
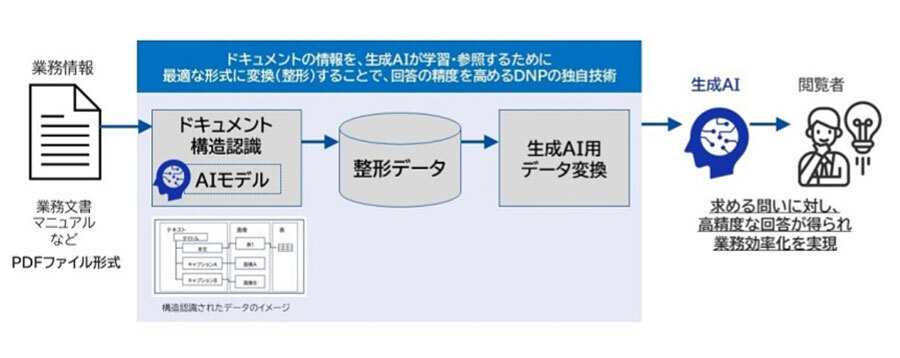
技術イメージ(出典:DNP)
同社は、企業や組織が生成AIを利用する際に、ユーザーが求める内容に適した回答を生成できなかったり、不要な内容を含んで回答をしてしまったりするなど、回答精度の低さが課題になっていると指摘する。このため、企業や組織が保有するドキュメントを生成AIの学習、参照向けに整形して、回答精度を向上させる今回の技術を開発した。
同社では、2023年5月に社内で生成AIを利用する環境を構築し、社内規定、品質マニュアル、決算短信などのドキュメントのデータを今回の技術で整形して、生成AIに学習、参照させる実証実験を行い、従来に比べて生成AIの誤回答を約90%削減する効果を認めたとする。ドキュメント内のコンテンツを解析するためのモデルは、一般的なディープラーニングでは数百~数千ページのデータを学習する必要があるものの、同社が開発した技術のモデルでは数十ページで可能になるという。
今回の技術を活用すれば、特に膨大なマニュアルやドキュメントを参照して業務を行う審査やコンタクトセンターの問い合わせ対応では、回答精度を高めて業務を効率化できる効果が期待されるとのこと。同社は、2024年1月に今回の技術を生成AIの導入や活用、生成AIのための学習データの加工や収集に課題を持つ企業および団体に提供することにしている。

DNPが自社の決算短信資料に適用した際の効果(出典:DNP)