日本オラクルは9月1日、専用機(アプライアンス)「Oracle Big Data Appliance」で稼働するソフトウェア「Oracle Big Data SQL」を発表、9月中に提供する。
同社は2020年にクラウドでナンバーワン企業となることを目標として掲げているが、「クラウド時代にはビッグデータ活用が企業の生命線になる」(日本オラクル 代表執行役社長兼最高経営責任者=CEO 杉原博茂氏)と説明。ビッグデータについても専任部隊、販売体制の強化、海外の最先端事例の紹介などとともに、新製品をはじめとした製品を拡充し、ビッグデータについても2020年に市場でナンバーワンとなることを目指す。
HDFSにも対応

日本オラクル 代表執行役社長兼CEO 杉原博茂氏
日本オラクルは「2020年にナンバーワンクラウド企業になる」という目標を掲げている。この目標と今回の新製品の関係について杉原氏は、「クラウド時代にはビッグデータの活用が企業の生命線となる」と説明した。
杉原氏は、調査データでも既に64%の企業が何らかの形で投資していることをあげ、「しかし、ビッグデータに投資した企業の57%が失敗に終わっているという調査結果も出ている。構造化データに加え、増加する一方の非構造化データを含め、複雑化するデータの処理、エンジニアのスキル経験不足によってリスクがさらに増している。その複雑さへの対応策としてBig Data SQLを提供する」と説明した。

日本オラクル 専務進行役員 データベース事業統括 三澤智光氏
Big Data SQLについて専務進行役員 データベース事業統括の三澤智光氏は、「リレーショナルデータだけでも、OracleだけでなくMicrosoftやIBMと異なるものをそれぞれ別に扱わなければいけないのか? という悩みをオラクル製品以外のリレーショナル製品のデータを透過的に扱うことで解決する。非構造化データについては、NoSQLとHadoopで扱い、あらゆるデータを一元的に管理する仕組みを提供する」と特徴を説明する。
Big Data SQLでは、XMLとJSONに対応するとともに、分散並列処理フレームワーク「Apache Hadoop」の標準の分散ファイルシステム「HDFS」にSQLで対応できるようになっている。超大規模なデータウェアハウス(DWH)の構築では、構造化と非構造化の両方のデータを透過的に分析できる。
また、ビッグデータ環境へ同社の堅牢なセキュリティをそのまま適用できるようにもなっている。同社のデータベース専用機「Oracle Exadata Database Machine」で培われた高速化機能を搭載している。
構造化データと非構造データを融合させたことでアプリケーションを改修せずにSQLで分析できる。高速処理については、Exadataの「Smart Scan」をHadoop側にも適用した。「Exadataがなぜ速いのかといえば、サーバで動くオラクルがストレージでも動くようにすることで究極の分散処理を実現していたから。この仕組みを新製品にも適用することで、高速化を実現した」(三澤氏)
構造化データと非構造化データを融合させて、新たなビッグデータ分析基盤として活用できるとし、「データ分析には、データサイエンティストだけでなく、一般社員も触れられるビッグデータ分析基盤となる製品」(三澤氏)だと説明している。
提供形態としては、Big Data Appliance上のソフトウェアオプションとして提供。利用のための前提条件としてExadataと「Oracle Database 12.1.0.2 Enterprise Edition」を導入していることとなっている。価格は現段階で未公表で、出荷と同時に発表する予定となっている。
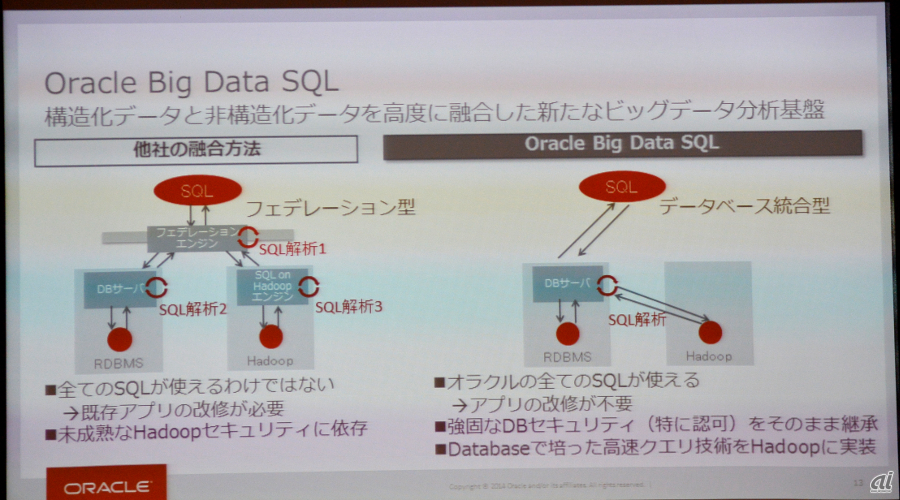
Big Data SQLはフェデレーション型ではなく統合型となっている





