正解は図1に書いてあるとおりです。ある人物が複数の部門を兼任しているとしたらどうでしょうか? 実際に存在する人間は一人だけなのに、組織上は複数の部門に所属し、存在してしまっています。このように、多対1や多対多のデータを表現する場合、1つのデータがデータベース内に複数存在してしまう「データの冗長」が発生してしまうのです。データの更新を行う際には、データの一貫性を保つために、一度にこの重複する全てのデータを書き換えなければならなくなり、大変な作業となってしまいます。
また、先程お話したように、ある1つのデータが他の複数のデータに対して親子の関係を持ちますので、データにアクセスするためのルートは一通りにしかなりません。ですので、それぞれのデータにアクセスする場合、階層構造を理解しておく必要があります。
このデータモデルの場合、物理的な構成が階層構造で表現されているので、それを利用することで効率的な検索ができるという利点がありますが、逆を言ってしまえば、効率よく検索する為には構造を理解し、順序など構造に関する多くの事を指定しないといけないということが言えます。当然、階層構造を変更した場合は、そのデータベースを利用しているプログラムはその変更に合わせて修正しなければなりません。このように階層型データモデルは、データ構造への強い依存性を持っています。これは次にお話しするネットワーク型でも言えることです。
ネットワーク型データベース
ネットワーク型データモデルに基づいてデータを管理するデータベースです。ネットワーク型データモデルは、基本的には階層型と似た構造をしています。それぞれのデータが網目のようにつながりあうのでネットワーク型と呼ばれます。
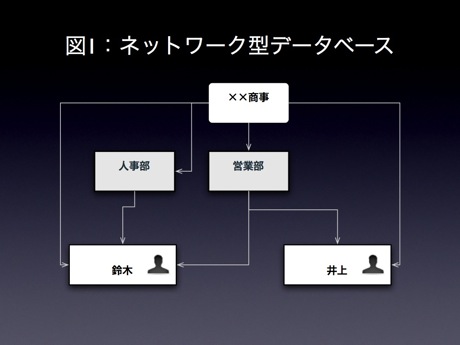 図2:ネットワーク型データベース
図2:ネットワーク型データベース
このデータモデルでは、1つの子データが複数の親データをもてる構造になっていますので、段階型データモデルで問題点であったデータの冗長性を排除できるような仕組みになっています。しかし、階層型と同じようにデータ構造を理解していないとデータにアクセスできないという、データ構造への強い依存性を持っています。
ちょっと余談ですが、このネットワーク型データモデルは1969年に、CODASYL(Conference on Data Systems Languages)という委員会によって最初の規格が策定されました。CODASYLは、プログラミング言語「COBOL」の言語仕様を決めた委員会です。このCODASYLの策定した「DBTG CODASYL方式」がネットワーク型の代表的な例となっています。
リレーショナル型データベース
リレーショナル・データモデルは、データを行と列で構成される二次元の表形式でデータを表現しています。図3のようなイメージです。図を見てみると何かに似ていると思いませんか? そうです。前回にも登場した表計算ソフトです。
 図3:リレーショナル型データベース
図3:リレーショナル型データベース
このようにリレーショナル・データベースは、データを「行」と「列」の2次元の構造で格納します。この「行」と「列」を指定することにより、取り出したいデータの値を取得することができます。また、複数の表を関連付けることができるので、自由な形式でデータを取り出すことができます。そして、SQLという問いあわせ言語を利用することにより、データベースの構築や問合せが簡単になりました。
では、リレーショナル・データベースの最大の利点って何だと思いますか?





